
















Ontgrendel de kracht van generatieve AI
use cases met data van hoge kwaliteit
Gegevens van hoge kwaliteit over meerdere gegevenstypen
dat wil zeggen, tekst, audio, beeld en video.

Beeld

Audio

Tekst

Video
250K uur. van artsenaudio, 25 miljoen EPD's
Meer dan 2 miljoen afbeeldingen (MRI's, CT's, XR's) voor ML-training




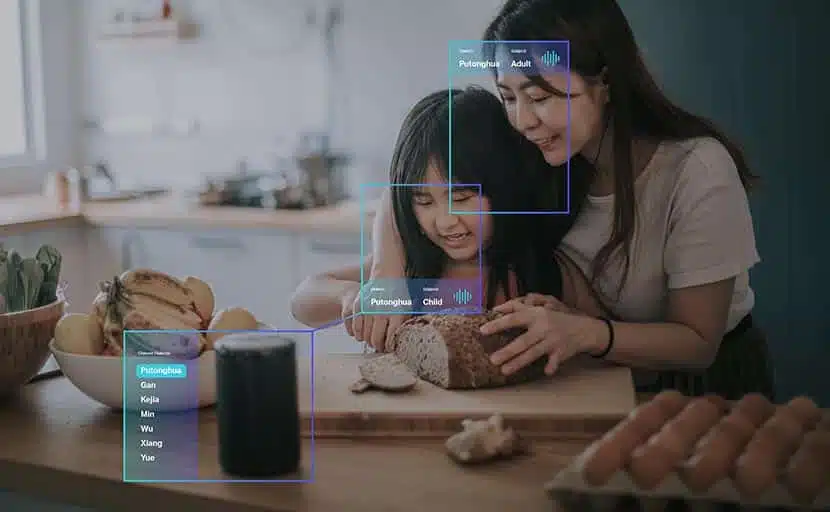
Meer dan 60,000 uur spraakgegevens van hoge kwaliteit
in meer dan 60 talen en dialecten



Teams in staat stellen om toonaangevende AI-producten te bouwen.
Krijg in een fractie van de tijd de hoogste kwaliteit gelabelde gegevens, dwz tekst, audio, afbeelding en video. Het is de gouden standaard, betrouwbaar en klaar om uw AI- en ML-modellen te trainen om de hoogste prestatieniveaus te bereiken.
Met Shaip krijg je meer dan 15 jaar expertise in het verzamelen, transcriberen en annoteren van kwaliteitsgegevens. Met ons wereldwijde personeelsbestand kunnen we gegevens van over de hele wereld verzamelen, transcriptie- en annotatiediensten leveren met het perfecte niveau van vereiste vaardigheden en expertise.
Met onze enorme voorraad van miljoenen datasets kunt u deze naar wens verzamelen en ordenen. We kunnen die kwaliteitsgegevens vervolgens licentiëren voor uw specifieke AI- en ML-gebruiksvereisten. Bovendien zijn deze gegevens beschikbaar tegen een fractie van de kosten als u ze zelf zou maken.
Bij Shaip bieden we een compleet scala aan trainingsgegevensdiensten, zoals AI-gegevensverzameling en -licenties, gegevensannotatie en -etikettering, gegevensde-identificatie, gegevenstranscriptie en meer om te voldoen aan uw specifieke machine learning- en AI-doelstellingen, budgetten en tijdframes.
De echte waarde van de cognitieve gegevensannotatie- en labelservices van Shaip is dat het organisaties de sleutel geeft om kritieke informatie te ontsluiten die diep in ongestructureerde gegevens te vinden is.
Wanneer klanten spreken over onze spraakverzameling en annotatie, hoor je succesverhalen. Vanaf dag één is Shaip toonaangevend op het gebied van AI-trainingsgegevens voor conversatie-AI en chatbots.
Van slimme auto's en slimme steden tot verbeterde smartphonecamera's en beveiligingstoezicht, het verzamelen en annoteren van afbeeldingen is een specialiteit die Shaip uitblinkt voor klanten over de hele wereld.
Shaip kan video annoteren voor machine learning-toepassingen die worden gebruikt in robotica voor verbeterde productie, autonoom rijdende auto's en zelfs het verbeteren van de koopervaring van een consument.
We gebruiken ons wereldwijde netwerk van gegevensmakers en materiedeskundigen om aan alle projectvereisten te voldoen. Als je strakke deadlines moet halen, geen probleem. Onze diensten kunnen op elk moment snel worden opgeschaald om gegevens in bijna elk formaat te leveren, zoals tekst, audio, beeld en video in een kort tijdsbestek.
Platform
Een compleet human-in-the-loop eigen platform voor het sourcen, transcriberen en annoteren van diverse datasets voor het succesvol implementeren van de meest veeleisende AI- en ML-initiatieven.
Mensen
Om AI slimmer te laten denken, zijn mensen nodig die tot de slimste koppen in de branche behoren. We kunnen opschalen naar duizenden van deze professionals over de hele wereld om alle gegevenstypen te transcriberen, te labelen en te annoteren.
Proces
Het leveren van gouden standaardgegevens die consistent, volledig en nauwkeurig zijn, is complex werk. Maar het is wat we altijd leveren, omdat we ons houden aan de hoogste kwaliteitsnormen en aan strenge en bewezen controles en controlepunten.
Gebruik Gevallen:
Specialiteiten:
Lees meer over ons schaalbare, on-demand platform waarmee teams trainingsgegevens kunnen genereren voor hun machine learning-modellen.
Wij garanderen de veiligheid en privacy van uw gegevens door deze op te slaan in een eersteklas faciliteit en door een toegewijd team van dataspecialisten op onze loonlijst in te zetten. Uw gegevens zijn van u. Shaip deelt nooit uw datasets.
We staan klaar om uw AI-projecten tot leven te brengen. Ben je?
© 2018 – 2024 Shaip | Alle rechten voorbehouden