
Automatische spraakherkenningssystemen en virtuele assistenten zoals Siri, Alexa en Cortana zijn gemeengoed geworden in ons leven. Onze afhankelijkheid van hen neemt aanzienlijk toe naarmate ze slimmer worden. Van het aandoen van onze lichten tot bellen tot het veranderen van tv-zenders, we gebruiken deze slimme technologieën om alledaagse taken uit te voeren.
Heb je je echter ooit afgevraagd hoe deze spraakherkenningssystemen werken?
Welnu, deze blog zal u informeren over enkele basisprincipes van automatische spraakherkenning. We zullen ook de werking ervan onderzoeken en hoe functionele virtuele assistenten zoals Siri worden gebouwd.
Wat is automatische spraakherkenning?
Automatische spraakherkenning (ASR) is software waarmee het computersysteem menselijke spraak in tekst kan omzetten, gebruikmakend van meerdere kunstmatige intelligentie- en machine learning-algoritmen.
Na het converteren en analyseren van het gegeven commando, reageert de computer met een geschikte uitvoer voor de gebruiker. ASR werd voor het eerst geïntroduceerd in 1962 en sindsdien is het continu bezig met het verbeteren van zijn activiteiten en krijgt het enorm veel aandacht vanwege populaire applicaties zoals Alexa en Siri.
Wat is het proces voor spraakverzameling voor het trainen van ASR-modellen?
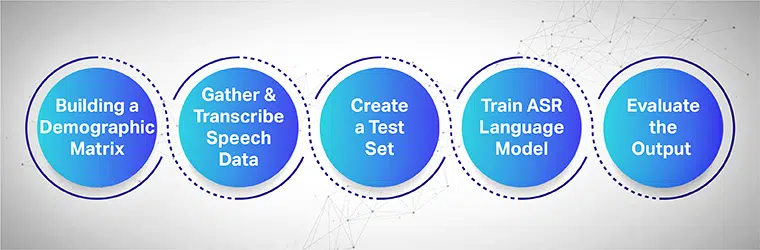
Spraakverzameling is bedoeld om verschillende voorbeeldopnamen te verzamelen uit meerdere gebieden die worden gebruikt om ASR-modellen te voeden en te trainen. Het ASR-systeem levert de hoogste efficiëntie wanneer grote datasets van spraak en audio worden verzameld en aan het systeem worden geleverd.
Om naadloos te werken, moeten de verzamelde spraakdatasets alle demografische doelgroepen, talen, accenten en dialecten bevatten. Het volgende proces laat zien hoe u het machine learning-model in meerdere stappen kunt trainen:
Begin met het bouwen van een demografische matrix
Verzamelt voornamelijk de gegevens voor verschillende demografische gegevens, zoals de locatie, geslachten, taal, leeftijden en accenten. Zorg er ook voor dat u een verscheidenheid aan omgevingsgeluiden vastlegt, zoals straatlawaai, wachtkamerlawaai, openbare kantoorlawaai, enz.
Verzamel en transcribeer de spraakgegevens
De volgende stap is het verzamelen van menselijke audio- en spraakmonsters op basis van verschillende geografische locaties om uw ASR-model te trainen. Het is een belangrijke stap en vereist dat menselijke experts lange en korte uitingen van woorden uitvoeren om het echte gevoel van de zin te krijgen en dezelfde zinnen in verschillende accenten en dialecten te herhalen.
Een aparte testset maken
Nadat u de getranscribeerde tekst hebt verzameld, is de volgende stap om deze te koppelen aan de bijbehorende audiogegevens. Segmenteer de gegevens vervolgens verder en neem er één verklaring van op. Nu kunt u uit de gesegmenteerde gegevensparen willekeurige gegevens uit een set halen om verder te testen.
Train je ASR Taalmodel
Hoe meer informatie uw datasets hebben, hoe beter uw AI-getrainde model zou presteren. Genereer daarom meerdere variaties van tekst en toespraken die u eerder hebt opgenomen. Parafraseer dezelfde zinnen met verschillende spraaknotaties.
Evalueer de output en ten slotte itereer
Meet ten slotte de output van uw ASR-model om de prestaties te verbeteren. Test het model tegen een testset om de efficiëntie te bepalen. Betrek uw ASR-model bij voorkeur in een feedbacklus om de gewenste output te genereren en eventuele hiaten op te lossen.
[Lees ook: Een uitgebreid overzicht van automatische spraakherkenning]

Wat zijn de verschillende use-cases van spraakherkenning?
Spraakherkenningstechnologie is tegenwoordig zeer gangbaar in veel industrieën. Sommige industrieën die deze geweldige technologie gebruiken, zijn als volgt:
 Voedselindustrie: Voedselreuzen als Wendy's en McDonald's gaan hun klantervaringen verbeteren met ASR. In veel van hun verkooppunten hebben ze volledig functionele ASR-modellen ingezet om bestellingen op te nemen en deze verder door te geven aan de kookafdeling om de bestelling van de klant klaar te maken.
Voedselindustrie: Voedselreuzen als Wendy's en McDonald's gaan hun klantervaringen verbeteren met ASR. In veel van hun verkooppunten hebben ze volledig functionele ASR-modellen ingezet om bestellingen op te nemen en deze verder door te geven aan de kookafdeling om de bestelling van de klant klaar te maken.- Telecommunicatie: Vodafone is een van de grootste telecomaanbieders ter wereld. Het heeft zijn klantenservice en telefonische doorschakelingsservices ontworpen met gebruikmaking van ASR-modellen die u begeleiden bij het oplossen van verschillende vragen en het omleiden van uw oproepen naar betrokken afdelingen.
- Reizen en vervoer: Google Android Auto of Apple CarPlay zijn gemeengoed geworden. De meeste mensen gebruiken ze om navigatiesystemen te activeren, berichten te verzenden of van muziekafspeellijst te wisselen. Met technologische vooruitgang worden dergelijke systemen echter steeds verfijnder.
BMW Intelligent Personal Assistant, gelanceerd in de BMW 3-serie, is veel slimmer dan gewone spraakassistenten. Hiermee kunnen bestuurders autogerelateerde informatie vinden en de auto bedienen met spraakopdrachten. - Media en amusement: Ook de media-industrie maakt bij veel van haar projecten gebruik van ASR. YouTube heeft een op AI gebaseerde assistent gelanceerd die live automatische ondertiteling genereert. Terwijl je op het scherm spreekt, zorgt de assistent voor de ondertitels om de video toegankelijk te maken voor een grotere groep YouTube-gebruikers.
 Voedselindustrie: Voedselreuzen als Wendy's en McDonald's gaan hun klantervaringen verbeteren met ASR. In veel van hun verkooppunten hebben ze volledig functionele ASR-modellen ingezet om bestellingen op te nemen en deze verder door te geven aan de kookafdeling om de bestelling van de klant klaar te maken.
Voedselindustrie: Voedselreuzen als Wendy's en McDonald's gaan hun klantervaringen verbeteren met ASR. In veel van hun verkooppunten hebben ze volledig functionele ASR-modellen ingezet om bestellingen op te nemen en deze verder door te geven aan de kookafdeling om de bestelling van de klant klaar te maken. Telecommunicatie: Vodafone is een van de grootste telecomaanbieders ter wereld. Het heeft zijn klantenservice en telefonische doorschakelingsservices ontworpen met gebruikmaking van ASR-modellen die u begeleiden bij het oplossen van verschillende vragen en het omleiden van uw oproepen naar betrokken afdelingen.
Telecommunicatie: Vodafone is een van de grootste telecomaanbieders ter wereld. Het heeft zijn klantenservice en telefonische doorschakelingsservices ontworpen met gebruikmaking van ASR-modellen die u begeleiden bij het oplossen van verschillende vragen en het omleiden van uw oproepen naar betrokken afdelingen. Reizen en vervoer: Google Android Auto of Apple CarPlay zijn gemeengoed geworden. De meeste mensen gebruiken ze om navigatiesystemen te activeren, berichten te verzenden of van muziekafspeellijst te wisselen. Met technologische vooruitgang worden dergelijke systemen echter steeds verfijnder.
Reizen en vervoer: Google Android Auto of Apple CarPlay zijn gemeengoed geworden. De meeste mensen gebruiken ze om navigatiesystemen te activeren, berichten te verzenden of van muziekafspeellijst te wisselen. Met technologische vooruitgang worden dergelijke systemen echter steeds verfijnder. Media en amusement: Ook de media-industrie maakt bij veel van haar projecten gebruik van ASR. YouTube heeft een op AI gebaseerde assistent gelanceerd die live automatische ondertiteling genereert. Terwijl je op het scherm spreekt, zorgt de assistent voor de ondertitels om de video toegankelijk te maken voor een grotere groep YouTube-gebruikers.
Media en amusement: Ook de media-industrie maakt bij veel van haar projecten gebruik van ASR. YouTube heeft een op AI gebaseerde assistent gelanceerd die live automatische ondertiteling genereert. Terwijl je op het scherm spreekt, zorgt de assistent voor de ondertitels om de video toegankelijk te maken voor een grotere groep YouTube-gebruikers.
[Lees ook: Wat is spraak-naar-teksttechnologie en hoe werkt het]
Hoe kan Shaip helpen?
Shaip is een van de toonaangevende AI-trainingsdiensten met expertise op meerdere gebieden van AI en ML. Zij kunnen u helpen bij het bouwen van uw eigen dataset die voor verschillende toepassingen en projecten kan worden gebruikt.
Enkele van de diensten van Shaip zijn:
- Geautomatiseerde spraakherkenning (ASR)
- Verzameling van gescripte spraak
- transcreatie
- Spontane spraakverzameling
- Uitingverzameling / Wake-up Words,
- Tekst-naar-spraak (TTS)
U kunt gebruik maken van deze services om de beste resultaten te behalen voor uw op AI gebaseerde projecten. Kom meer te weten over deze services door vandaag nog contact op te nemen met ons deskundige team!


