
Een robuuste, op AI gebaseerde oplossing is gebaseerd op gegevens - niet zomaar gegevens, maar hoogwaardige, nauwkeurig geannoteerde gegevens. Alleen de beste en meest verfijnde gegevens kunnen uw AI-project van stroom voorzien, en deze gegevenszuiverheid zal een enorme impact hebben op het projectresultaat.
We hebben data vaak de brandstof voor AI-projecten genoemd, maar niet zomaar alle data is voldoende. Als je raketbrandstof nodig hebt om je project te helpen opstijgen, kun je geen ruwe olie in de tank doen. In plaats daarvan moeten gegevens (zoals brandstof) zorgvuldig worden verfijnd om ervoor te zorgen dat alleen informatie van de hoogste kwaliteit uw project aandrijft. Dat verfijningsproces wordt data-annotatie genoemd en er bestaan nogal wat hardnekkige misvattingen over.
Definieer de kwaliteit van trainingsgegevens in annotatie
We weten dat datakwaliteit een groot verschil maakt voor de uitkomst van het AI-project. Enkele van de beste en best presterende ML-modellen zijn gebaseerd op gedetailleerde en nauwkeurig gelabelde datasets.
Maar hoe definiëren we kwaliteit precies in een annotatie?
Als we het hebben over gegevens annotatie kwaliteit, nauwkeurigheid, betrouwbaarheid en consistentie zijn belangrijk. Er wordt gezegd dat een dataset nauwkeurig is als deze overeenkomt met de grondwaarheid en real-world informatie.
Consistentie van gegevens verwijst naar het nauwkeurigheidsniveau dat in de hele dataset wordt gehandhaafd. De kwaliteit van een dataset wordt echter nauwkeuriger bepaald door het type project, de unieke vereisten en het gewenste resultaat. Daarom zouden dit de criteria moeten zijn voor het bepalen van de kwaliteit van gegevenslabels en annotaties.
Waarom is het belangrijk om datakwaliteit te definiëren?
Het is belangrijk om datakwaliteit te definiëren, aangezien het fungeert als een allesomvattende factor die de kwaliteit van het project en het resultaat bepaalt.
- Gegevens van slechte kwaliteit kunnen de product- en bedrijfsstrategieën beïnvloeden.
- Een machine learning-systeem is zo goed als de kwaliteit van de gegevens waarop het is getraind.
- Gegevens van goede kwaliteit elimineert herwerk en de daaraan verbonden kosten.
- Het helpt bedrijven om weloverwogen projectbeslissingen te nemen en zich te houden aan de naleving van de regelgeving.
Hoe meten we de kwaliteit van trainingsgegevens tijdens het labelen?

Er zijn verschillende methoden om de kwaliteit van trainingsgegevens te meten, en de meeste beginnen met het maken van een concrete richtlijn voor gegevensannotatie. Enkele van de methoden zijn:
Benchmarks opgesteld door experts
Kwaliteitsbenchmarks of gouden standaard annotatie methoden zijn de gemakkelijkste en meest betaalbare opties voor kwaliteitsborging die dienen als referentiepunt voor het meten van de kwaliteit van de projectoutput. Het meet de gegevensannotaties ten opzichte van de benchmark die door de experts is vastgesteld.
Cronbach's Alpha-test
Cronbach's alpha-test bepaalt de correlatie of consistentie tussen dataset-items. De betrouwbaarheid van het label en grotere nauwkeurigheid kan worden gemeten op basis van het onderzoek.
Consensusmeting
Consensusmeting bepaalt de mate van overeenstemming tussen machine- of menselijke annotators. Over het algemeen moet er consensus worden bereikt voor elk item en moet worden gearbitreerd in geval van onenigheid.
Paneelbeoordeling
Een panel van deskundigen bepaalt meestal de nauwkeurigheid van het label door gegevenslabels te beoordelen. Soms wordt een bepaald deel van datalabels meestal als steekproef genomen om de nauwkeurigheid te bepalen.
Herziening Trainingsdata Kwaliteit
De bedrijven die AI-projecten aannemen, zijn volledig in de ban van de kracht van automatisering, en daarom blijven velen denken dat automatische annotatie op basis van AI sneller en nauwkeuriger zal zijn dan handmatig annoteren. Voorlopig is de realiteit dat er mensen nodig zijn om gegevens te identificeren en te classificeren, omdat nauwkeurigheid zo belangrijk is. De extra fouten die door automatische labeling worden gecreëerd, vereisen extra iteraties om de nauwkeurigheid van het algoritme te verbeteren, waardoor tijdwinst teniet wordt gedaan.
Een andere misvatting - en een die waarschijnlijk bijdraagt aan het gebruik van automatische annotatie - is dat kleine fouten niet veel effect hebben op de resultaten. Zelfs de kleinste fouten kunnen aanzienlijke onnauwkeurigheden veroorzaken vanwege een fenomeen dat AI-drift wordt genoemd, waarbij inconsistenties in invoergegevens een algoritme leiden in een richting die programmeurs nooit hebben bedoeld.
De kwaliteit van de trainingsgegevens - de aspecten nauwkeurigheid en consistentie - worden consequent beoordeeld om te voldoen aan de unieke eisen van de projecten. Een beoordeling van de trainingsgegevens wordt meestal uitgevoerd met behulp van twee verschillende methoden:
Automatisch geannoteerde technieken
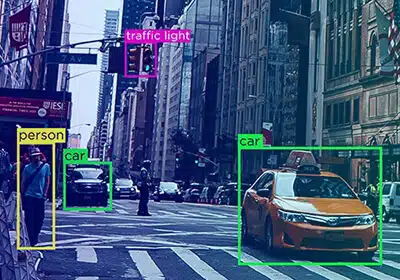 Het automatische beoordelingsproces voor annotaties zorgt ervoor dat feedback wordt teruggevoerd naar het systeem en voorkomt drogredenen, zodat annotators hun processen kunnen verbeteren.
Het automatische beoordelingsproces voor annotaties zorgt ervoor dat feedback wordt teruggevoerd naar het systeem en voorkomt drogredenen, zodat annotators hun processen kunnen verbeteren.
Automatische annotatie op basis van kunstmatige intelligentie is nauwkeurig en sneller. Automatische annotatie vermindert de tijd die handmatige QA's besteden aan het beoordelen, waardoor ze meer tijd kunnen besteden aan complexe en kritieke fouten in de dataset. Automatische annotatie kan ook helpen bij het detecteren van ongeldige antwoorden, herhalingen en onjuiste annotaties.
Handmatig via data science-experts
Gegevenswetenschappers beoordelen ook gegevensannotaties om nauwkeurigheid en betrouwbaarheid in de gegevensset te garanderen.
Kleine fouten en onnauwkeurigheden in de annotatie kunnen de uitkomst van het project aanzienlijk beïnvloeden. En deze fouten worden mogelijk niet gedetecteerd door de tools voor het automatisch beoordelen van annotaties. Datawetenschappers voeren steekproefkwaliteitstests uit van verschillende batchgroottes om inconsistenties en onbedoelde fouten in de dataset te detecteren.
Achter elke AI-kop zit een annotatieproces en Shaip kan helpen om het pijnloos te maken
Valkuilen bij AI-projecten vermijden
Veel organisaties worden geplaagd door een gebrek aan interne annotatiebronnen. Er is veel vraag naar datawetenschappers en ingenieurs, en het inhuren van genoeg van deze professionals om een AI-project op zich te nemen, betekent een cheque uitschrijven die voor de meeste bedrijven onbereikbaar is. In plaats van een budgetoptie te kiezen (zoals crowdsourcing-annotatie) die u uiteindelijk zal blijven achtervolgen, kunt u overwegen uw annotatiebehoeften uit te besteden aan een ervaren externe partner. Outsourcing zorgt voor een hoge mate van nauwkeurigheid en vermindert tegelijkertijd de knelpunten van aanwerving, training en beheer die ontstaan wanneer u probeert een intern team samen te stellen.
Wanneer u uw annotatiebehoeften specifiek aan Shaip uitbesteedt, maakt u gebruik van een krachtige kracht die uw AI-initiatief kan versnellen zonder de snelkoppelingen die de allerbelangrijkste resultaten in gevaar brengen. We bieden een volledig beheerd personeelsbestand, wat betekent dat u een veel grotere nauwkeurigheid kunt krijgen dan u zou bereiken door middel van crowdsourcing-annotatie-inspanningen. De initiële investering is misschien hoger, maar het loont tijdens het ontwikkelingsproces wanneer er minder iteraties nodig zijn om het gewenste resultaat te bereiken.
Onze dataservices dekken ook het hele proces, inclusief sourcing, een mogelijkheid die de meeste andere labelingproviders niet kunnen bieden. Met onze ervaring kunt u snel en eenvoudig grote hoeveelheden hoogwaardige, geografisch diverse gegevens verkrijgen die geanonimiseerd zijn en voldoen aan alle relevante regelgeving. Wanneer u deze gegevens onderbrengt in ons cloudgebaseerde platform, krijgt u ook toegang tot beproefde tools en workflows die de algehele efficiëntie van uw project verhogen en u helpen sneller vooruitgang te boeken dan u voor mogelijk had gehouden.
En tot slot, onze interne branche-experts uw unieke behoeften begrijpen. Of u nu een chatbot bouwt of gezichtsherkenningstechnologie toepast om de gezondheidszorg te verbeteren, wij zijn er geweest en kunnen u helpen bij het ontwikkelen van richtlijnen die ervoor zorgen dat het annotatieproces de doelen bereikt die voor uw project zijn geschetst.
Bij Shaip zijn we niet alleen enthousiast over het nieuwe tijdperk van AI. We helpen het op ongelooflijke manieren, en onze ervaring heeft ons geholpen om talloze succesvolle projecten van de grond te krijgen. Neem contact met ons op om te zien wat we voor uw eigen implementatie kunnen betekenen: vraag een demo aan <p></p>


