Het internet heeft de deuren geopend voor mensen die vrijelijk hun mening, mening en suggesties kunnen uiten over zo ongeveer alles ter wereld social media, websites en blogs. Naast het uiten van hun mening beïnvloeden mensen (klanten) ook de koopbeslissingen van anderen. Het sentiment, of het nu negatief of positief is, is van cruciaal belang voor elk bedrijf of merk dat zich zorgen maakt over de verkoop van zijn producten of diensten.
Bedrijven helpen de opmerkingen voor zakelijk gebruik te ontginnen Natural Language Processing. Een op de vier bedrijven heeft plannen om NLP-technologie binnen een jaar te implementeren om hun zakelijke beslissingen te ondersteunen. Met behulp van sentimentanalyse helpt NLP bedrijven interpreteerbare inzichten te ontlenen aan ruwe en ongestructureerde gegevens.
Opiniemining of sentiment analyse is een techniek van NLP die wordt gebruikt om het exacte sentiment te identificeren - positief, negatief of neutraal - geassocieerd met opmerkingen en feedback. Met behulp van NLP worden trefwoorden in de commentaren geanalyseerd om de positieve of negatieve woorden in het trefwoord te bepalen.
Sentimenten worden gescoord op een schaalsysteem dat sentimentscores toekent aan emoties in een stuk tekst (waarbij de tekst als positief of negatief wordt bepaald).
Wat is meertalige sentimentanalyse?

Zoals de naam al doet vermoeden, meertalige sentimentanalyse is de techniek van het uitvoeren van sentimentscores voor meer dan één taal. Zo eenvoudig is het echter niet. Onze cultuur, taal en ervaringen hebben grote invloed op ons koopgedrag en onze emoties. Zonder een goed begrip van de taal, context en cultuur van de gebruiker is het onmogelijk om de intenties, emoties en interpretaties van gebruikers nauwkeurig te begrijpen.
Terwijl automatisering het antwoord is op veel van onze hedendaagse problemen, machine vertaling software zal niet in staat zijn om de nuances van de taal, spreektaal, subtiliteiten en culturele verwijzingen op te pikken in de commentaren en product beoordelingen het is aan het vertalen. De ML-tool kan u een vertaling geven, maar is mogelijk niet nuttig. Dat is de reden waarom meertalige sentimentanalyse vereist is.
Waarom is meertalige sentimentanalyse nodig?
De meeste bedrijven gebruiken Engels als hun communicatiemedium, maar het wordt niet door de meeste consumenten wereldwijd gebruikt.
Volgens Ethnologue spreekt ongeveer 13% van de wereldbevolking Engels. Bovendien stelt de British Council dat ongeveer 25% van de wereldbevolking een behoorlijke kennis van het Engels heeft. Als we deze cijfers mogen geloven, communiceert een groot deel van de consumenten met elkaar en met het bedrijf in een andere taal dan het Engels.
Als het belangrijkste doel van bedrijven is om hun klantenbestand intact te houden en nieuwe klanten aan te trekken, moet het de meningen van hun klanten die in hun moedertaal. Het handmatig beoordelen van elke opmerking of het vertalen ervan in het Engels is een omslachtig proces dat geen effectieve resultaten zal opleveren.
Een duurzame oplossing is om meertalig te ontwikkelen systemen voor sentimentanalyse die meningen, emoties en suggesties van klanten op sociale media, forums, enquêtes en meer detecteren en analyseren.
Stappen om meertalige sentimentanalyse uit te voeren
Sentimentanalyse, ongeacht of het in één taal of in één taal is meerdere talen, is een proces dat de toepassing van machine learning-modellen, natuurlijke taalverwerking en data-analysetechnieken vereist om te extraheren meertalige sentimentscore uit de gegevens.
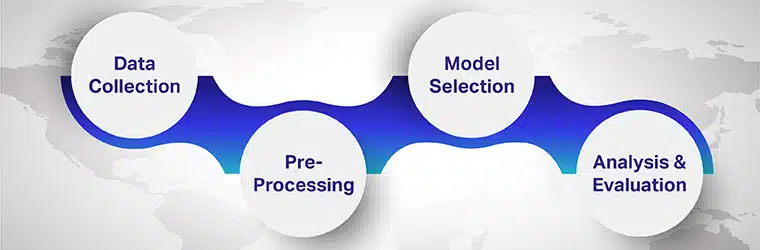
De stappen die betrokken zijn bij meertalige sentimentanalyse zijn
Stap 1: gegevens verzamelen
Het verzamelen van gegevens is de eerste stap bij het toepassen van sentimentanalyse. Om een meertalig sentimentanalyse model, is het belangrijk om gegevens in verschillende talen te verzamelen. Alles hangt af van de kwaliteit van de verzamelde, geannoteerde en gelabelde gegevens. U kunt gegevens halen uit API's, open-sourcerepository's en uitgevers.
Stap 2: Voorbewerking
De verzamelde webgegevens moeten worden opgeschoond en er moet informatie uit worden gehaald. De delen van de tekst die geen specifieke betekenis hebben, zoals 'de' 'is' en meer, moeten worden verwijderd. Verder moet de tekst worden gegroepeerd in woordgroepen om te worden gecategoriseerd om een positieve of negatieve betekenis over te brengen.
Om de classificatiekwaliteit te verbeteren, moet de inhoud worden ontdaan van ruis, zoals HTML-tags, advertenties en scripts. Taal, lexicon en grammatica die door mensen worden gebruikt, verschillen afhankelijk van het sociale netwerk. Het is belangrijk om dergelijke inhoud te normaliseren en voor te bereiden op voorbewerking.
Een andere cruciale stap in de voorverwerking is het gebruik van natuurlijke taalverwerking om zinnen te splitsen, stopwoorden te verwijderen, delen van spraak te taggen, woorden om te zetten in hun hoofdvorm en woorden om te zetten in symbolen en tekst.
Stap 3: Modelselectie
Op regels gebaseerd model: De eenvoudigste methode voor meertalige semantische analyse is op regels gebaseerd. Het op regels gebaseerde algoritme voert de analyse uit op basis van een reeks vooraf bepaalde regels die door de experts zijn geprogrammeerd.
De regel kan woorden of woordgroepen specificeren die positief of negatief zijn. Als u bijvoorbeeld een product- of dienstrecensie neemt, kan deze positieve of negatieve woorden bevatten, zoals 'geweldig', 'traag', 'wacht' en 'nuttig'. Deze methode maakt het gemakkelijk om woorden te classificeren, maar het kan ingewikkelde of minder frequente woorden verkeerd classificeren.
Automatisch model: Het automatische model voert een meertalige sentimentanalyse uit zonder tussenkomst van menselijke moderators. Hoewel het machine learning-model met menselijke inspanning is gebouwd, kan het automatisch werken om nauwkeurige resultaten te leveren zodra het is ontwikkeld.
Testgegevens worden geanalyseerd en elke opmerking wordt handmatig gemarkeerd als positief of negatief. Het ML-model leert vervolgens van de testgegevens door de nieuwe tekst te vergelijken met de bestaande opmerkingen en deze te categoriseren.
Stap 4: Analyse en evaluatie
De op regels gebaseerde en machine-learning-modellen kunnen in de loop van de tijd en ervaring worden verbeterd en uitgebreid. Een lexicon van minder vaak gebruikte woorden of live scores voor meertalige sentimenten kan worden bijgewerkt voor snellere en nauwkeurigere classificatie.
De uitdaging van vertalen
Is vertalen niet genoeg? Eigenlijk niet!
Vertalen omvat het overbrengen van tekst of tekstgroepen uit de ene taal en het vinden van een equivalent in een andere. Vertalen is echter noch eenvoudig noch effectief.
Dat komt omdat mensen taal niet alleen gebruiken om hun behoeften kenbaar te maken, maar ook om hun emoties te uiten. Bovendien zijn er grote verschillen tussen verschillende talen, zoals Engels, Hindi, Mandarijn en Thai. Voeg aan deze literaire mix het gebruik van emoties, jargon, idioom, sarcasme en emoji's toe. Het is niet mogelijk om een nauwkeurige vertaling van de tekst te krijgen.
Enkele van de belangrijkste uitdagingen van machine vertaling zijn
- Subjectiviteit
- Context
- Slang en Idioom
- Sarcasme
- Vergelijkingen
- Neutraliteit
- Emoji's en modern gebruik van woorden.
Zonder de bedoelde betekenis van de beoordelingen, opmerkingen en communicatie over hun producten, prijzen, diensten, functies en kwaliteit nauwkeurig te begrijpen, zullen bedrijven de behoeften en meningen van klanten niet kunnen begrijpen.
Meertalige sentimentanalyse is een uitdagend proces. Elke taal heeft zijn unieke lexicon, syntaxis, morfologie en fonologie. Voeg daarbij de cultuur, jargon, gevoelens uitgedrukt, sarcasme en tonaliteit, en je hebt een uitdagende puzzel die een efficiënte AI-aangedreven ML-oplossing nodig heeft.
Er is een uitgebreide meertalige dataset nodig om robuuste meertaligheid te ontwikkelen tools voor sentimentanalyse die beoordelingen kan verwerken en bedrijven krachtige inzichten kan bieden. Shaip is de marktleider in het leveren van op maat gemaakte, gelabelde, geannoteerde datasets in verschillende talen die helpen bij het ontwikkelen van efficiënte en nauwkeurige meertalige oplossingen voor sentimentanalyse.