
Introductie
Deze gids zal zeer nuttig zijn voor die kopers en besluitvormers die hun gedachten beginnen te richten op de moeren en bouten van datasourcing en data-implementatie, zowel voor neurale netwerken als voor andere soorten AI- en ML-operaties.

Dit artikel is volledig gewijd aan het werpen van licht op wat het proces is, waarom het onvermijdelijk, cruciaal is
factoren waarmee bedrijven rekening moeten houden bij het benaderen van tools voor gegevensannotatie en meer. Dus, als u een bedrijf heeft, bereid u dan voor om geïnformeerd te worden, want deze gids leidt u door alles wat u moet weten over gegevensannotatie.
Laten we beginnen.
Voor degenen onder u die het artikel doorbladeren, zijn hier enkele snelle afhaalrestaurants die u in de gids vindt:
- Begrijpen wat gegevensannotatie is
- Ken de verschillende soorten gegevensannotatieprocessen
- Ken de voordelen van het implementeren van het gegevensannotatieproces
- Krijg duidelijkheid over of u voor in-house data-etikettering moet gaan of ze moet uitbesteden
- Ook inzicht in het kiezen van de juiste gegevensannotatie
Wat is machinaal leren?
 We hebben het gehad over hoe gegevensannotatie of data-etikettering machine learning ondersteunt en dat het bestaat uit het taggen of identificeren van componenten. Maar wat betreft deep learning en machine learning zelf: het uitgangspunt van machine learning is dat computersystemen en programma's hun output kunnen verbeteren op manieren die lijken op menselijke cognitieve processen, zonder directe menselijke hulp of tussenkomst, om ons inzichten te geven. Met andere woorden, het worden zelflerende machines die, net als een mens, door meer oefening beter worden in hun werk. Deze “oefening” krijg je door meer (en betere) trainingsdata te analyseren en interpreteren.
We hebben het gehad over hoe gegevensannotatie of data-etikettering machine learning ondersteunt en dat het bestaat uit het taggen of identificeren van componenten. Maar wat betreft deep learning en machine learning zelf: het uitgangspunt van machine learning is dat computersystemen en programma's hun output kunnen verbeteren op manieren die lijken op menselijke cognitieve processen, zonder directe menselijke hulp of tussenkomst, om ons inzichten te geven. Met andere woorden, het worden zelflerende machines die, net als een mens, door meer oefening beter worden in hun werk. Deze “oefening” krijg je door meer (en betere) trainingsdata te analyseren en interpreteren.
Wat is gegevensannotatie?
Gegevensannotatie is het proces van het toekennen, taggen of labelen van gegevens om machine learning-algoritmen te helpen de informatie die ze verwerken te begrijpen en te classificeren. Dit proces is essentieel voor het trainen van AI-modellen, waardoor ze verschillende gegevenstypen nauwkeurig kunnen begrijpen, zoals afbeeldingen, audiobestanden, videobeelden of tekst.
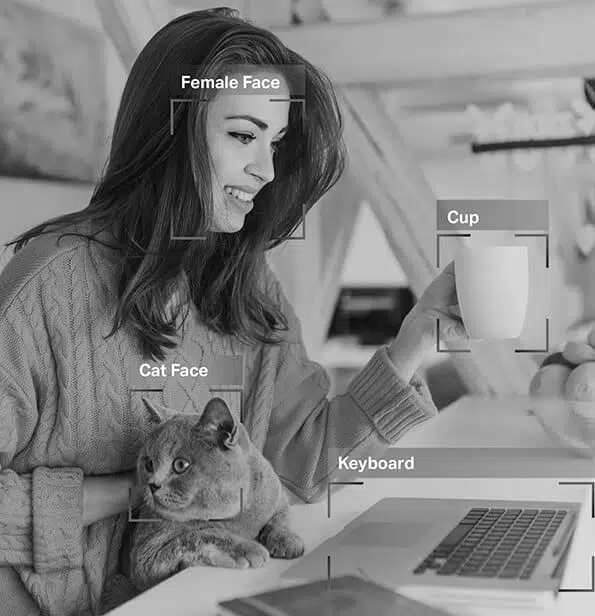
Stel je een zelfrijdende auto voor die vertrouwt op gegevens van computervisie, natuurlijke taalverwerking (NLP) en sensoren om nauwkeurige rijbeslissingen te nemen. Om het AI-model van de auto te helpen onderscheid te maken tussen obstakels zoals andere voertuigen, voetgangers, dieren of wegversperringen, moeten de ontvangen gegevens worden gelabeld of geannoteerd.
Bij gesuperviseerd leren is data-annotatie vooral cruciaal, aangezien hoe meer gelabelde data aan het model worden toegevoerd, hoe sneller het leert autonoom te functioneren. Met geannoteerde gegevens kunnen AI-modellen worden ingezet in verschillende toepassingen, zoals chatbots, spraakherkenning en automatisering, wat resulteert in optimale prestaties en betrouwbare resultaten.
Wat is een tool voor het labelen/annoteren van gegevens?
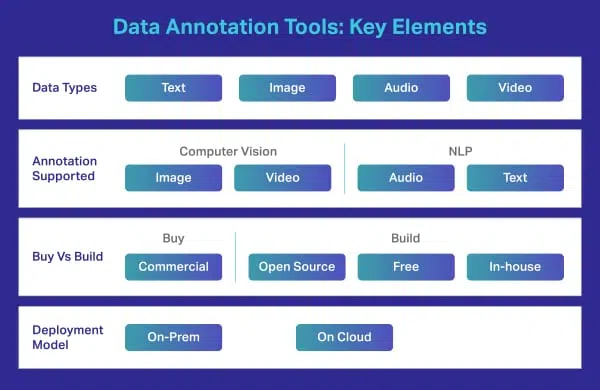 In eenvoudige bewoordingen is het een platform of een portal waarmee specialisten en experts allerlei soorten datasets kunnen annoteren, labelen of labelen. Het is een brug of een medium tussen onbewerkte gegevens en de resultaten die uw machine learning-modules uiteindelijk zouden opleveren.
In eenvoudige bewoordingen is het een platform of een portal waarmee specialisten en experts allerlei soorten datasets kunnen annoteren, labelen of labelen. Het is een brug of een medium tussen onbewerkte gegevens en de resultaten die uw machine learning-modules uiteindelijk zouden opleveren.
Een tool voor het labelen van gegevens is een on-prem of cloudgebaseerde oplossing die hoogwaardige trainingsgegevens annoteert voor machine learning-modellen. Hoewel veel bedrijven afhankelijk zijn van een externe leverancier om complexe aantekeningen te maken, hebben sommige organisaties nog steeds hun eigen tools die op maat zijn gemaakt of gebaseerd zijn op freeware of opensource-tools die op de markt verkrijgbaar zijn. Dergelijke tools zijn meestal ontworpen om specifieke gegevenstypen te verwerken, zoals afbeeldingen, video, tekst, audio, enz. De tools bieden functies of opties zoals begrenzingsvakken of polygonen voor gegevensannotators om afbeeldingen te labelen. Ze kunnen gewoon de optie selecteren en hun specifieke taken uitvoeren.
Annotatie afbeelding

Op basis van de datasets waarop ze zijn getraind, kunnen ze onmiddellijk en nauwkeurig uw ogen van uw neus en uw wenkbrauw van uw wimpers onderscheiden. Daarom passen de filters die je toepast perfect, ongeacht de vorm van je gezicht, hoe dicht je bij je camera bent en meer.
Dus, zoals je nu weet, afbeelding annotatie is van vitaal belang in modules met gezichtsherkenning, computervisie, robotvisie en meer. Wanneer AI-experts dergelijke modellen trainen, voegen ze bijschriften, identifiers en trefwoorden toe als attributen aan hun afbeeldingen. De algoritmen identificeren en begrijpen vervolgens deze parameters en leren autonoom.
Beeldclassificatie – Beeldclassificatie omvat het toewijzen van vooraf gedefinieerde categorieën of labels aan afbeeldingen op basis van hun inhoud. Dit type annotatie wordt gebruikt om AI-modellen te trainen om afbeeldingen automatisch te herkennen en te categoriseren.
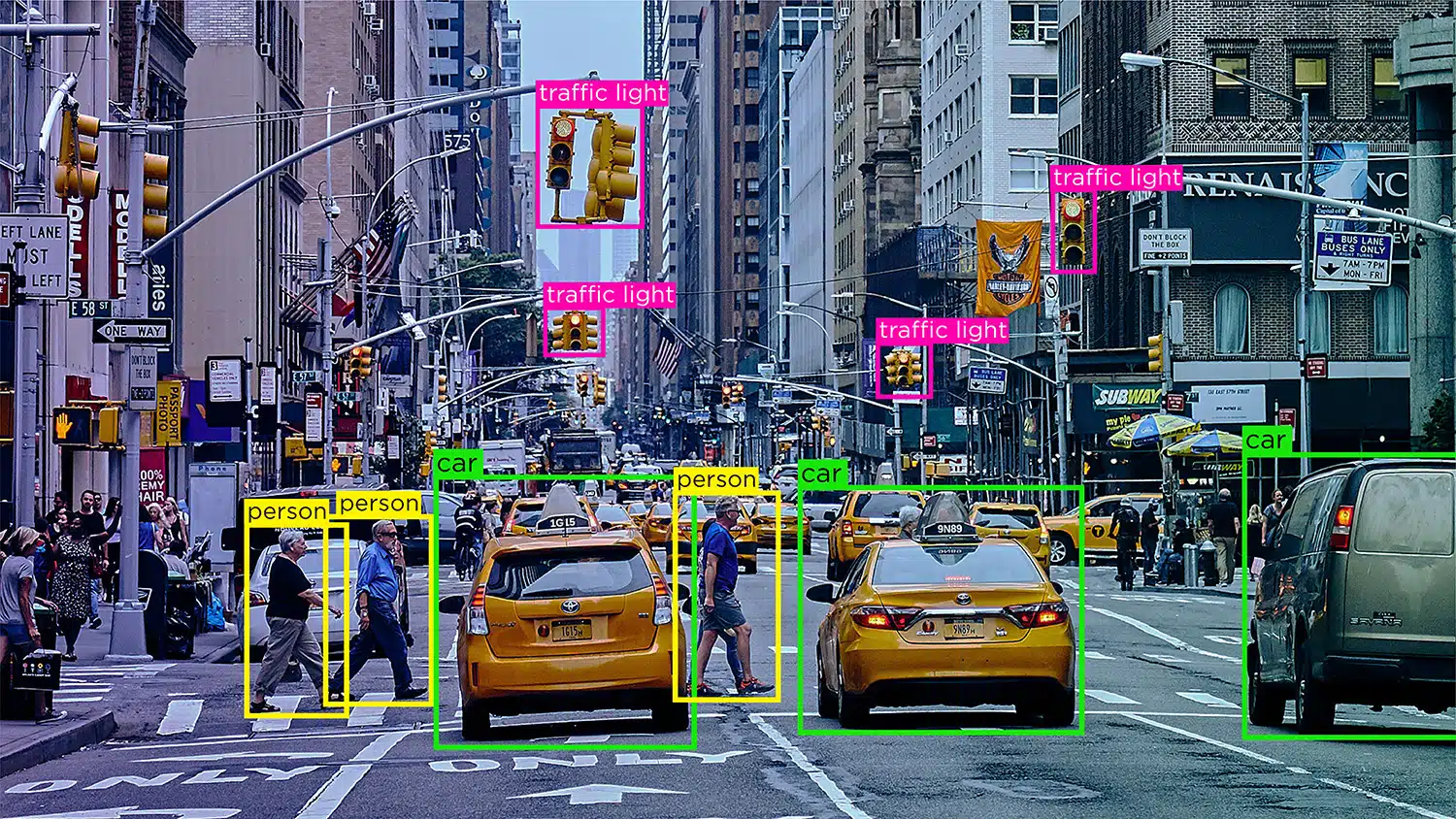
Objectherkenning/detectie – Objectherkenning, of objectdetectie, is het proces van het identificeren en labelen van specifieke objecten binnen een afbeelding. Dit type annotatie wordt gebruikt om AI-modellen te trainen om objecten in real-world afbeeldingen of video's te lokaliseren en te herkennen.
Segmentatie – Beeldsegmentatie omvat het verdelen van een beeld in meerdere segmenten of regio's, die elk overeenkomen met een specifiek object of interessegebied. Dit type annotatie wordt gebruikt om AI-modellen te trainen om afbeeldingen op pixelniveau te analyseren, waardoor objectherkenning en scènebegrip nauwkeuriger worden.
Audio-annotatie
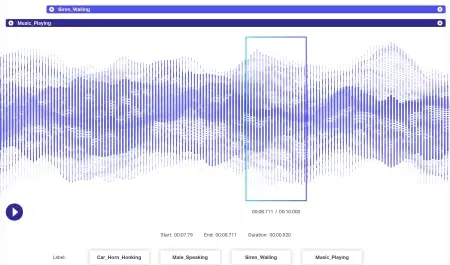
Aan audiodata is nog meer dynamiek verbonden dan aan beelddata. Verschillende factoren zijn geassocieerd met een audiobestand, inclusief maar zeker niet beperkt tot: taal, demografie van de spreker, dialecten, stemming, intentie, emotie, gedrag. Om ervoor te zorgen dat algoritmen efficiënt kunnen worden verwerkt, moeten al deze parameters worden geïdentificeerd en getagd door technieken zoals tijdstempels, audiolabels en meer. Naast alleen verbale signalen, kunnen non-verbale gevallen zoals stilte, ademhalingen en zelfs achtergrondgeluiden worden geannoteerd zodat systemen volledig kunnen worden begrepen.
Videoannotatie

Terwijl een afbeelding stil is, is een video een compilatie van afbeeldingen die het effect creëren van bewegende objecten. Nu wordt elke afbeelding in deze compilatie een frame genoemd. Wat video-annotatie betreft, omvat het proces de toevoeging van keypoints, polygonen of begrenzingsvakken om verschillende objecten in het veld in elk frame te annoteren.
Wanneer deze frames aan elkaar worden genaaid, kunnen de beweging, het gedrag, de patronen en meer door de AI-modellen in actie worden geleerd. Het is alleen door video-annotatie dat concepten als lokalisatie, bewegingsonscherpte en objecttracking in systemen kunnen worden geïmplementeerd.
Tekstannotatie

Tegenwoordig zijn de meeste bedrijven afhankelijk van op tekst gebaseerde gegevens voor uniek inzicht en informatie. Nu kan tekst van alles zijn, van feedback van klanten over een app tot een vermelding op sociale media. En in tegenstelling tot afbeeldingen en video's die meestal duidelijke bedoelingen overbrengen, bevat tekst veel semantiek.
Als mensen zijn we afgestemd op het begrijpen van de context van een zin, de betekenis van elk woord, elke zin of zin, deze te relateren aan een bepaalde situatie of conversatie en vervolgens de holistische betekenis achter een uitspraak te realiseren. Machines daarentegen kunnen dit niet op precieze niveaus. Begrippen als sarcasme, humor en andere abstracte elementen zijn hen onbekend en daarom wordt het labelen van tekstgegevens moeilijker. Daarom heeft tekstannotatie enkele meer verfijnde fasen, zoals de volgende:
Semantische annotatie – objecten, producten en diensten worden relevanter gemaakt door geschikte trefwoordtags en identificatieparameters. Chatbots zijn ook gemaakt om op deze manier menselijke gesprekken na te bootsen.
Intentie annotatie – de intentie van een gebruiker en de taal die door hen wordt gebruikt, zijn getagd zodat machines ze kunnen begrijpen. Hiermee kunnen modellen onderscheid maken tussen een verzoek van een opdracht, of een aanbeveling van een boeking, enzovoort.
Sentiment annotatie - Sentimentannotatie omvat het labelen van tekstgegevens met het sentiment dat het overbrengt, zoals positief, negatief of neutraal. Dit type annotatie wordt vaak gebruikt bij sentimentanalyse, waarbij AI-modellen worden getraind om de in tekst uitgedrukte emoties te begrijpen en te evalueren.

Entiteit annotatie – waar ongestructureerde zinnen worden getagd om ze betekenisvoller te maken en ze in een formaat te brengen dat door machines kan worden begrepen. Om dit mogelijk te maken, zijn twee aspecten betrokken: genoemde entiteitsherkenning en entiteit koppelen. Erkenning van benoemde entiteiten is wanneer namen van plaatsen, mensen, gebeurtenissen, organisaties en meer worden getagd en geïdentificeerd en entiteitskoppeling is wanneer deze tags worden gekoppeld aan zinnen, zinsdelen, feiten of meningen die erop volgen. Gezamenlijk leggen deze twee processen de relatie tussen de bijbehorende teksten en de verklaring eromheen.
Tekstcategorisatie – Zinnen of paragrafen kunnen worden getagd en geclassificeerd op basis van overkoepelende onderwerpen, trends, onderwerpen, meningen, categorieën (sport, entertainment en dergelijke) en andere parameters.
Belangrijkste stappen in het proces van gegevenslabeling en gegevensannotatie
Het data-annotatieproces omvat een reeks goed gedefinieerde stappen om hoogwaardige en nauwkeurige datalabeling voor machine learning-toepassingen te garanderen. Deze stappen omvatten elk aspect van het proces, van het verzamelen van gegevens tot het exporteren van de geannoteerde gegevens voor verder gebruik.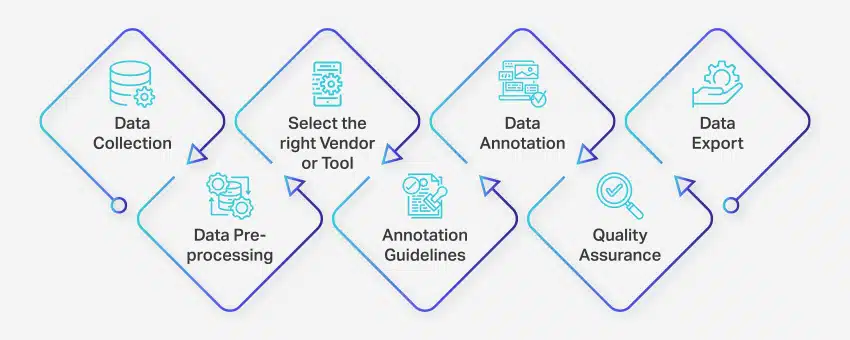
Zo vindt gegevensannotatie plaats:
- Gegevensverzameling: De eerste stap in het gegevensannotatieproces is het verzamelen van alle relevante gegevens, zoals afbeeldingen, video's, audio-opnamen of tekstgegevens, op een centrale locatie.
- Gegevens voorverwerking: Standaardiseer en verbeter de verzamelde gegevens door afbeeldingen recht te trekken, tekst op te maken of video-inhoud te transcriberen. Preprocessing zorgt ervoor dat de gegevens klaar zijn voor annotatie.
- Selecteer de juiste leverancier of tool: Kies een geschikte data-annotatietool of leverancier op basis van de vereisten van uw project. Opties zijn onder andere platforms zoals Nanonets voor data-annotatie, V7 voor beeld-annotatie, Appen voor video-annotatie en Nanonets voor document-annotatie.
- Richtlijnen voor annotaties: Stel duidelijke richtlijnen op voor annotators of annotatietools om consistentie en nauwkeurigheid gedurende het hele proces te garanderen.
- annotatie: Label en tag de gegevens met behulp van menselijke annotators of data-annotatiesoftware, volgens de vastgestelde richtlijnen.
- Kwaliteitsborging (QA): Controleer de geannoteerde gegevens om nauwkeurigheid en consistentie te garanderen. Gebruik indien nodig meerdere blinde annotaties om de kwaliteit van de resultaten te controleren.
- Gegevens exporteren: Na het voltooien van de gegevensannotatie exporteert u de gegevens in het vereiste formaat. Platforms zoals Nanonets maken naadloze gegevensexport naar verschillende zakelijke softwaretoepassingen mogelijk.
Het gehele data-annotatieproces kan variëren van enkele dagen tot enkele weken, afhankelijk van de omvang, complexiteit en beschikbare middelen van het project.
Functies voor hulpmiddelen voor gegevensannotatie en gegevenslabels
Tools voor gegevensannotatie zijn doorslaggevende factoren die uw AI-project kunnen maken of breken. Als het gaat om nauwkeurige outputs en resultaten, maakt de kwaliteit van datasets alleen niet uit. De tools voor gegevensannotatie die u gebruikt om uw AI-modules te trainen, hebben zelfs een enorme invloed op uw output.
Daarom is het essentieel om de meest functionele en geschikte tool voor het labelen van gegevens te selecteren en te gebruiken die voldoet aan de behoeften van uw bedrijf of project. Maar wat is in de eerste plaats een tool voor gegevensannotatie? Welk doel dient het? Zijn er soorten? Nou, laten we het uitzoeken.
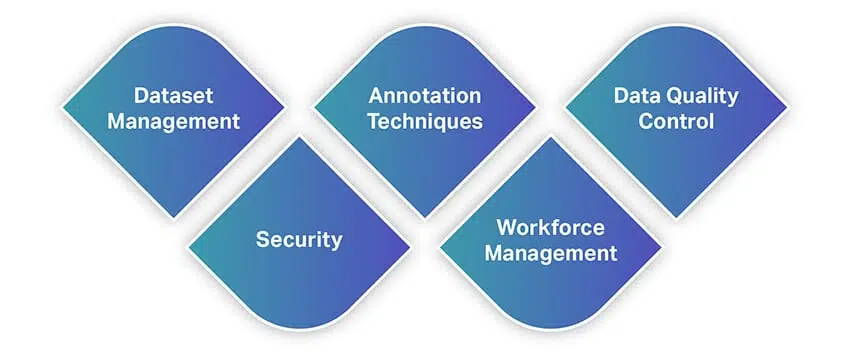
Net als andere tools bieden tools voor gegevensannotatie een breed scala aan functies en mogelijkheden. Om u snel een idee te geven van functies, volgt hier een lijst met enkele van de meest fundamentele functies waar u op moet letten bij het selecteren van een hulpmiddel voor gegevensannotatie.
Datasetbeheer
De tool voor gegevensannotatie die u wilt gebruiken, moet de gegevenssets die u bij de hand heeft ondersteunen en u kunt ze in de software importeren om ze te labelen. Het beheren van uw datasets is dus de belangrijkste functie die tools bieden. Hedendaagse oplossingen bieden functies waarmee u grote hoeveelheden gegevens naadloos kunt importeren, terwijl u tegelijkertijd uw gegevenssets kunt ordenen door middel van acties zoals sorteren, filteren, klonen, samenvoegen en meer.
Zodra de invoer van uw datasets is voltooid, exporteert u ze als bruikbare bestanden. Met de tool die u gebruikt, kunt u uw datasets opslaan in het formaat dat u opgeeft, zodat u ze in uw ML-modellen kunt invoeren.
Annotatietechnieken
Dit is waar een tool voor gegevensannotatie voor is gebouwd of ontworpen. Een solide tool zou u een reeks annotatietechnieken moeten bieden voor alle soorten datasets. Dit is tenzij u een aangepaste oplossing voor uw behoeften ontwikkelt. Met uw tool kunt u video's of afbeeldingen annoteren vanuit computervisie, audio of tekst van NLP's en transcripties en meer. Om dit verder te verfijnen, zouden er opties moeten zijn om begrenzingsvakken, semantische segmentatie, kubussen, interpolatie, sentimentanalyse, woordsoorten, coreferentie-oplossing en meer te gebruiken.
Voor niet-ingewijden zijn er ook AI-aangedreven tools voor gegevensannotatie. Deze worden geleverd met AI-modules die autonoom leren van de werkpatronen van een annotator en automatisch afbeeldingen of tekst annoteren. Zo een
modules kunnen worden gebruikt om annotators ongelooflijke hulp te bieden, annotaties te optimaliseren en zelfs kwaliteitscontroles uit te voeren.
Controle van gegevenskwaliteit
Over kwaliteitscontroles gesproken, er worden verschillende tools voor gegevensannotatie uitgerold met ingebouwde kwaliteitscontrolemodules. Deze stellen annotators in staat beter samen te werken met hun teamleden en helpen bij het optimaliseren van workflows. Met deze functie kunnen annotators opmerkingen of feedback in realtime markeren en volgen, identiteiten volgen achter mensen die wijzigingen in bestanden aanbrengen, eerdere versies herstellen, kiezen voor het labelen van consensus en meer.
Security
Aangezien u met gegevens werkt, moet beveiliging de hoogste prioriteit hebben. Mogelijk werkt u aan vertrouwelijke gegevens, zoals persoonlijke gegevens of intellectueel eigendom. Uw tool moet dus een waterdichte beveiliging bieden wat betreft waar de gegevens worden opgeslagen en hoe deze worden gedeeld. Het moet tools bieden die de toegang tot teamleden beperken, ongeautoriseerde downloads voorkomen en meer.
Afgezien hiervan moeten beveiligingsnormen en -protocollen worden nageleefd en nageleefd.
Workforce Management
Een tool voor gegevensannotatie is ook een soort projectbeheerplatform, waar taken aan teamleden kunnen worden toegewezen, samenwerking kan plaatsvinden, beoordelingen mogelijk zijn en meer. Daarom moet uw tool in uw workflow en proces passen voor optimale productiviteit.
Bovendien moet de tool ook een minimale leercurve hebben, aangezien het proces van gegevensannotatie op zich al tijdrovend is. Het heeft geen enkel nut om te veel tijd te besteden aan het leren van de tool. Het moet dus intuïtief en naadloos zijn voor iedereen om snel aan de slag te kunnen.
Wat zijn de voordelen van gegevensannotatie?
Gegevensannotatie is cruciaal voor het optimaliseren van machine learning-systemen en het leveren van verbeterde gebruikerservaringen. Hier volgen enkele belangrijke voordelen van gegevensannotatie:
- Verbeterde trainingsefficiëntie: Gegevenslabeling helpt machine learning-modellen beter te trainen, de algehele efficiëntie te verbeteren en nauwkeurigere resultaten te produceren.
- Verhoogde precisie: Nauwkeurig geannoteerde gegevens zorgen ervoor dat algoritmen zich effectief kunnen aanpassen en leren, wat resulteert in hogere niveaus van precisie bij toekomstige taken.
- Verminderde menselijke tussenkomst: Geavanceerde tools voor het annoteren van gegevens verminderen de behoefte aan handmatige interventie aanzienlijk, stroomlijnen processen en verlagen de bijbehorende kosten.
Zo draagt data-annotatie bij aan efficiëntere en nauwkeurigere machine learning-systemen, terwijl de kosten en handmatige inspanningen die traditioneel nodig zijn om AI-modellen te trainen, worden geminimaliseerd.
Een tool voor gegevensannotatie bouwen of niet bouwen
Een kritiek en overkoepelend probleem dat zich kan voordoen tijdens een project voor gegevensannotatie of gegevenslabels, is de keuze om functionaliteit voor deze processen te bouwen of te kopen. Dit kan meerdere keren voorkomen in verschillende projectfasen, of gerelateerd zijn aan verschillende onderdelen van het programma. Bij de keuze om intern een systeem te bouwen of op leveranciers te vertrouwen, is er altijd een afweging.

Zoals u nu waarschijnlijk kunt zien, is het annoteren van gegevens een complex proces. Tegelijkertijd is het ook een subjectief proces. Dit betekent dat er niet één enkel antwoord is op de vraag of u een tool voor gegevensannotatie moet kopen of bouwen. Er moeten veel factoren in overweging worden genomen en u moet uzelf enkele vragen stellen om uw vereisten te begrijpen en te beseffen of u er echt een moet kopen of bouwen.
Om dit eenvoudig te maken, zijn hier enkele van de factoren waarmee u rekening moet houden.
Jou doel
Het eerste element dat u moet definiëren, is het doel met uw kunstmatige intelligentie en machine learning-concepten.
- Waarom pas je ze toe in je bedrijf?
- Lossen ze een reëel probleem op waarmee uw klanten worden geconfronteerd?
- Maken ze een front-end- of backend-proces?
- Ga je AI gebruiken om nieuwe features te introduceren of je bestaande website, app of een module te optimaliseren?
- Wat doet uw concurrent in uw segment?
- Heb je genoeg use-cases die AI-interventie nodig hebben?
Antwoorden hierop zullen je gedachten - die momenteel overal kunnen zijn - op één plek samenbrengen en je meer duidelijkheid geven.
AI-gegevensverzameling / licentieverlening
AI-modellen hebben slechts één element nodig om te functioneren: gegevens. U moet identificeren van waaruit u enorme hoeveelheden grondwaarheidsgegevens kunt genereren. Als uw bedrijf grote hoeveelheden gegevens genereert die moeten worden verwerkt voor cruciale inzichten over zaken, bedrijfsvoering, concurrentieonderzoek, marktvolatiliteitsanalyse, onderzoek naar klantgedrag en meer, dan heeft u een hulpmiddel voor gegevensannotatie nodig. Houd echter ook rekening met de hoeveelheid gegevens die u genereert. Zoals eerder vermeld, is een AI-model slechts zo effectief als de kwaliteit en kwantiteit van de gegevens die het krijgt. Uw beslissingen moeten dus altijd van deze factor afhangen.
Als u niet over de juiste gegevens beschikt om uw ML-modellen te trainen, kunnen leveranciers erg handig zijn, omdat ze u kunnen helpen bij het in licentie geven van de juiste set gegevens die nodig zijn om ML-modellen te trainen. In sommige gevallen zal een deel van de waarde die de leverancier met zich meebrengt, zowel technische bekwaamheid als toegang tot middelen omvatten die het succes van projecten zullen bevorderen.
Budget
Nog een fundamentele voorwaarde die waarschijnlijk van invloed is op elke factor die we momenteel bespreken. De oplossing voor de vraag of u een gegevensannotatie moet bouwen of kopen, wordt eenvoudig als u begrijpt of u voldoende budget te besteden heeft.
Nalevingscomplexiteit
 Leveranciers kunnen zeer behulpzaam zijn als het gaat om gegevensprivacy en de juiste omgang met gevoelige gegevens. Een van deze soorten gebruiksscenario's betreft een ziekenhuis- of zorggerelateerd bedrijf dat de kracht van machine learning wil gebruiken zonder de naleving van HIPAA en andere gegevensprivacyregels in gevaar te brengen. Zelfs buiten het medische veld verscherpen wetten zoals de Europese AVG de controle op datasets en vereisen ze meer waakzaamheid van de zakelijke belanghebbenden.
Leveranciers kunnen zeer behulpzaam zijn als het gaat om gegevensprivacy en de juiste omgang met gevoelige gegevens. Een van deze soorten gebruiksscenario's betreft een ziekenhuis- of zorggerelateerd bedrijf dat de kracht van machine learning wil gebruiken zonder de naleving van HIPAA en andere gegevensprivacyregels in gevaar te brengen. Zelfs buiten het medische veld verscherpen wetten zoals de Europese AVG de controle op datasets en vereisen ze meer waakzaamheid van de zakelijke belanghebbenden.
Mankracht
Gegevensannotatie vereist bekwame mankracht om aan te werken, ongeacht de grootte, schaal en domein van uw bedrijf. Zelfs als u elke dag een absoluut minimum aan gegevens genereert, hebt u gegevensexperts nodig om aan uw gegevens te werken voor etikettering. Dus nu moet u zich realiseren of u over de benodigde mankracht beschikt. Zo ja, zijn ze dan bekwaam in de vereiste tools en technieken of hebben ze bijscholing nodig? Als ze bijscholing nodig hebben, heb je dan het budget om ze op te leiden?
Bovendien nemen de beste programma's voor het annoteren en labelen van gegevens een aantal materie- of domeinexperts en segmenteren ze op basis van demografie, zoals leeftijd, geslacht en expertisegebied - of vaak in termen van de gelokaliseerde talen waarmee ze zullen werken. Dat is, nogmaals, waar we bij Shaip praten over het krijgen van de juiste mensen op de juiste stoelen en zo de juiste mens-in-the-loop-processen aan te sturen die uw programmatische inspanningen naar succes zullen leiden.
Kleine en grote projectactiviteiten en kostendrempels
In veel gevallen kan leveranciersondersteuning meer een optie zijn voor een kleiner project of voor kleinere projectfasen. Wanneer de kosten beheersbaar zijn, kan het bedrijf profiteren van outsourcing om projecten voor gegevensannotatie of gegevenslabeling efficiënter te maken.
Bedrijven kunnen ook kijken naar belangrijke drempels - waarbij veel leveranciers de kosten koppelen aan de hoeveelheid data die wordt verbruikt of andere benchmarks voor hulpbronnen. Laten we bijvoorbeeld zeggen dat een bedrijf zich heeft aangemeld bij een leverancier voor het uitvoeren van de vervelende gegevensinvoer die nodig is voor het opzetten van testsets.
Er kan een verborgen drempel in de overeenkomst zijn waar de zakenpartner bijvoorbeeld een ander blok AWS-gegevensopslag of een ander servicecomponent van Amazon Web Services of een andere externe leverancier moet afsluiten. Dat geven ze door aan de klant in de vorm van hogere kosten, en daarmee komt het prijskaartje buiten bereik van de klant.
In deze gevallen helpt het meten van de services die u van leveranciers krijgt om het project betaalbaar te houden. Het hebben van de juiste scope zorgt ervoor dat de projectkosten niet hoger zijn dan wat redelijk of haalbaar is voor het bedrijf in kwestie.
Open source- en freeware-alternatieven
 Sommige alternatieven voor volledige leveranciersondersteuning omvatten het gebruik van open-sourcesoftware, of zelfs freeware, om gegevensannotatie- of labelprojecten uit te voeren. Hier is er een soort middenweg waar bedrijven niet alles vanaf het begin creëren, maar ook vermijden te veel te vertrouwen op commerciële leveranciers.
Sommige alternatieven voor volledige leveranciersondersteuning omvatten het gebruik van open-sourcesoftware, of zelfs freeware, om gegevensannotatie- of labelprojecten uit te voeren. Hier is er een soort middenweg waar bedrijven niet alles vanaf het begin creëren, maar ook vermijden te veel te vertrouwen op commerciële leveranciers.
De doe-het-zelf-mentaliteit van open source is zelf een soort compromis: ingenieurs en interne mensen kunnen profiteren van de open source-gemeenschap, waar gedecentraliseerde gebruikersbases hun eigen soorten ondersteuning bieden. Het zal niet hetzelfde zijn als wat u van een leverancier krijgt - u krijgt geen 24/7 gemakkelijke hulp of antwoord op vragen zonder intern onderzoek te doen - maar het prijskaartje is lager.
Dus de grote vraag: wanneer moet je een tool voor gegevensannotatie kopen:
Zoals bij veel soorten hightechprojecten, vereist dit soort analyse - wanneer te bouwen en wanneer te kopen - toegewijde aandacht en overweging over hoe deze projecten worden aangekocht en beheerd. De uitdagingen waarmee de meeste bedrijven worden geconfronteerd met betrekking tot AI/ML-projecten bij het overwegen van de "build" -optie, is dat het niet alleen om de bouw- en ontwikkelingsgedeelten van het project gaat. Er is vaak een enorme leercurve om zelfs maar op het punt te komen waarop echte AI/ML-ontwikkeling kan plaatsvinden. Met nieuwe AI/ML-teams en -initiatieven is het aantal 'onbekende onbekenden' veel groter dan het aantal 'bekende onbekenden'.
| Bouw | Kopen |
|---|---|
Voors:
| Voors:
|
nadelen:
| nadelen:
|
Houd rekening met de volgende aspecten om het nog eenvoudiger te maken:
- wanneer u aan enorme hoeveelheden gegevens werkt
- wanneer u aan verschillende soorten gegevens werkt
- wanneer de functionaliteiten van uw modellen of oplossingen in de toekomst kunnen veranderen of evolueren
- wanneer je een vage of generieke use case hebt
- wanneer u een duidelijk idee wilt hebben van de kosten die gemoeid zijn met het inzetten van een tool voor gegevensannotatie
- en wanneer u niet over het juiste personeel of bekwame experts beschikt om aan de tools te werken en op zoek bent naar een minimale leercurve
Als uw antwoorden tegengesteld waren aan deze scenario's, moet u zich concentreren op het bouwen van uw tool.
Hoe u de juiste tool voor gegevensannotatie kiest voor uw project
Als je dit leest, klinken deze ideeën opwindend en zijn ze zeker makkelijker gezegd dan gedaan. Dus hoe ga je om met het benutten van de overvloed aan reeds bestaande tools voor gegevensannotatie die er zijn? De volgende stap is dus het overwegen van de factoren die samenhangen met het kiezen van de juiste tool voor gegevensannotatie.
In tegenstelling tot een paar jaar geleden, is de markt tegenwoordig geëvolueerd met talloze tools voor gegevensannotatie in de praktijk. Bedrijven hebben meer opties om er een te kiezen op basis van hun specifieke behoeften. Maar elke afzonderlijke tool heeft zijn eigen reeks voor- en nadelen. Om een verstandige beslissing te nemen, moet er naast subjectieve eisen ook een objectieve weg worden bewandeld.
Laten we eens kijken naar enkele van de cruciale factoren waarmee u rekening moet houden in het proces.
Uw gebruiksscenario definiëren
Om de juiste tool voor gegevensannotatie te selecteren, moet u uw gebruiksscenario definiëren. U moet zich realiseren of uw vereiste tekst, beeld, video, audio of een mix van alle gegevenstypen betreft. Er zijn stand-alone tools die u kunt kopen en er zijn holistische tools waarmee u diverse acties op datasets kunt uitvoeren.
De tools van vandaag zijn intuïtief en bieden u opties op het gebied van opslagfaciliteiten (netwerk, lokaal of cloud), annotatietechnieken (audio, beeld, 3D en meer) en tal van andere aspecten. U kunt een tool kiezen op basis van uw specifieke vereisten.
Normen voor kwaliteitscontrole vaststellen
 Dit is een cruciale factor om te overwegen, aangezien het doel en de efficiëntie van uw AI-modellen afhankelijk zijn van de kwaliteitsnormen die u vaststelt. Net als bij een audit moet u kwaliteitscontroles uitvoeren van de gegevens die u invoert en de verkregen resultaten om te begrijpen of uw modellen op de juiste manier en voor de juiste doeleinden worden getraind. De vraag is echter: hoe denkt u kwaliteitsnormen vast te stellen?
Dit is een cruciale factor om te overwegen, aangezien het doel en de efficiëntie van uw AI-modellen afhankelijk zijn van de kwaliteitsnormen die u vaststelt. Net als bij een audit moet u kwaliteitscontroles uitvoeren van de gegevens die u invoert en de verkregen resultaten om te begrijpen of uw modellen op de juiste manier en voor de juiste doeleinden worden getraind. De vraag is echter: hoe denkt u kwaliteitsnormen vast te stellen?
Zoals met veel verschillende soorten taken, kunnen veel mensen gegevens annoteren en taggen, maar ze doen dit met verschillende mate van succes. Wanneer u om een dienst vraagt, verifieert u niet automatisch het niveau van kwaliteitscontrole. Daarom variëren de resultaten.
Dus wil je een consensusmodel inzetten, waarbij annotators feedback geven over de kwaliteit en corrigerende maatregelen direct worden genomen? Of geeft u de voorkeur aan voorbeeldreview, gouden standaarden of intersectie boven vakbondsmodellen?
Het beste koopplan zorgt ervoor dat de kwaliteitscontrole vanaf het begin aanwezig is door normen vast te stellen voordat een definitief contract wordt overeengekomen. Bij het vaststellen hiervan mag u ook de foutmarges niet over het hoofd zien. Handmatig ingrijpen kan niet volledig worden vermeden, aangezien systemen onvermijdelijk fouten produceren tot 3%. Dit vergt wel wat werk van tevoren, maar het is het waard.
Wie zal uw gegevens annoteren?
De volgende belangrijke factor hangt af van wie uw gegevens annoteert. Ben je van plan om een in-house team te hebben of wil je dit liever uitbesteden? Als u uitbesteedt, zijn er wettigheids- en nalevingsmaatregelen die u moet overwegen vanwege de privacy- en vertrouwelijkheidsproblemen die verband houden met gegevens. En als u een intern team heeft, hoe efficiënt zijn ze dan in het leren van een nieuwe tool? Wat is uw time-to-market met uw product of dienst? Beschikt u over de juiste kwaliteitsstatistieken en teams om de resultaten goed te keuren?
De verkoper vs. Partnerdebat
 Het annoteren van gegevens is een samenwerkingsproces. Het gaat om afhankelijkheden en fijne kneepjes zoals interoperabiliteit. Dit betekent dat bepaalde teams altijd met elkaar samenwerken en dat een van de teams uw leverancier kan zijn. Daarom is de leverancier of partner die u selecteert net zo belangrijk als de tool die u gebruikt voor het labelen van gegevens.
Het annoteren van gegevens is een samenwerkingsproces. Het gaat om afhankelijkheden en fijne kneepjes zoals interoperabiliteit. Dit betekent dat bepaalde teams altijd met elkaar samenwerken en dat een van de teams uw leverancier kan zijn. Daarom is de leverancier of partner die u selecteert net zo belangrijk als de tool die u gebruikt voor het labelen van gegevens.
Met deze factor moeten aspecten zoals het vermogen om uw gegevens en bedoelingen vertrouwelijk te houden, de intentie om feedback te accepteren en eraan te werken, proactief zijn in termen van gegevensaanvragen, flexibiliteit in operaties en meer, worden overwogen voordat u een leverancier of een partner de hand schudt . We hebben flexibiliteit ingebouwd omdat de vereisten voor gegevensannotatie niet altijd lineair of statisch zijn. Ze kunnen in de toekomst veranderen naarmate u uw bedrijf verder opschaalt. Als u momenteel alleen te maken heeft met op tekst gebaseerde gegevens, wilt u misschien audio- of videogegevens annoteren terwijl u schaalt en uw ondersteuning zou klaar moeten zijn om hun horizon met u te verbreden.
Leveranciersbetrokkenheid
Een van de manieren om de betrokkenheid van leveranciers te beoordelen, is de ondersteuning die u krijgt.
Bij elk koopplan moet rekening worden gehouden met dit onderdeel. Hoe ziet de ondersteuning er op de grond uit? Wie zullen de belanghebbenden en de mensen aan beide kanten van de vergelijking zijn?
Er zijn ook concrete taken die duidelijk moeten maken wat de betrokkenheid van de leverancier is (of zal zijn). Zal de leverancier voor een gegevensannotatie- of gegevenslabelproject in het bijzonder actief de onbewerkte gegevens verstrekken of niet? Wie treden op als materiedeskundigen en wie zal hen in dienst nemen als werknemers of als onafhankelijke contractanten?
Casestudies
Hier zijn enkele specifieke voorbeelden van casestudy's die ingaan op hoe gegevensannotatie en gegevenslabels echt in de praktijk werken. Bij Shaip zorgen we ervoor dat we de hoogste kwaliteitsniveaus en superieure resultaten bieden op het gebied van gegevensannotatie en gegevenslabels.
Veel van de bovenstaande bespreking van standaardprestaties voor gegevensannotatie en gegevenslabeling onthult hoe we elk project benaderen en wat we bieden aan de bedrijven en belanghebbenden waarmee we werken.
Casestudy-materiaal dat laat zien hoe dit werkt:

In een klinisch datalicentieproject heeft het Shaip-team meer dan 6,000 uur aan audio verwerkt, alle beschermde gezondheidsinformatie (PHI) verwijderd en HIPAA-compatibele inhoud achtergelaten voor spraakherkenningsmodellen in de gezondheidszorg om aan te werken.
In dit soort gevallen zijn het de criteria en het classificeren van prestaties die belangrijk zijn. De onbewerkte gegevens zijn in de vorm van audio en het is nodig om partijen te de-identificeren. Bij het gebruik van NER-analyse is het tweeledige doel bijvoorbeeld om de inhoud te de-identificeren en te annoteren.
Een andere case study omvat een diepgaande Conversatie AI-trainingsgegevens project dat we voltooiden met 3,000 taalkundigen die gedurende een periode van 14 weken aan het werk waren. Dit leidde tot de productie van trainingsgegevens in 27 talen, om meertalige digitale assistenten te ontwikkelen die in staat zijn om met menselijke interacties om te gaan in een brede selectie van moedertalen.
In deze specifieke case study was de noodzaak om de juiste persoon op de juiste stoel te krijgen duidelijk. Het grote aantal materiedeskundigen en operators voor contentinvoer betekende dat er behoefte was aan organisatie en procedurele stroomlijning om het project binnen een bepaalde tijdlijn af te ronden. Ons team was in staat om de industriestandaard met een ruime marge te verslaan door het verzamelen van gegevens en de daaropvolgende processen te optimaliseren.
Andere soorten casestudy's omvatten zaken als bottraining en tekstannotatie voor machine learning. Nogmaals, in een tekstformaat is het nog steeds belangrijk om geïdentificeerde partijen te behandelen volgens de privacywetten en om de onbewerkte gegevens te doorzoeken om de beoogde resultaten te krijgen.
Met andere woorden, bij het werken met meerdere gegevenstypen en -indelingen heeft Shaip hetzelfde essentiële succes aangetoond door dezelfde methoden en principes toe te passen op zowel onbewerkte gegevens als bedrijfsscenario's voor gegevenslicenties.