

Intelligente AI-modellen moeten uitgebreid worden getraind om patronen en objecten te kunnen identificeren en uiteindelijk betrouwbare beslissingen te kunnen nemen. De getrainde gegevens kunnen echter niet willekeurig worden ingevoerd en moeten worden gelabeld om de modellen te helpen bij het begrijpen, verwerken en volledig leren van de samengestelde invoerpatronen.
Dit is waar datalabeling binnenkomt, als een handeling van het labelen van informatie of liever metadata, volgens een specifieke dataset, om zich te concentreren op het vergroten van het begrip van de machines. Om eenvoudigweg verder te gaan, categoriseert gegevenslabels selectief gegevens, afbeeldingen, tekst, audio, video's en patronen om AI-implementaties te verbeteren.
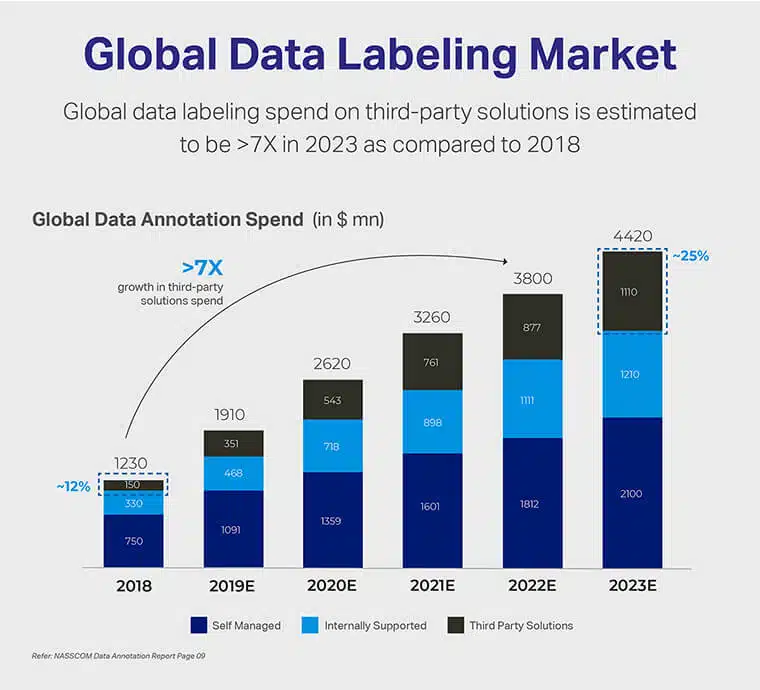
Vanaf NASSCOM Gegevenslabels Volgens het rapport zal de wereldwijde markt voor data-etikettering naar verwachting tegen het einde van 700 met 2023% in waarde groeien in vergelijking met 2018. Deze vermeende groei zal hoogstwaarschijnlijk een rol spelen bij de financiële toewijzing voor zelfbeheerde etiketteringstools, intern ondersteund bronnen en zelfs oplossingen van derden.
Naast deze bevindingen kan ook worden geconcludeerd dat de wereldwijde markt voor gegevensetikettering in 1.2 een waarde van $ 2018 miljard vergaarde. We verwachten echter dat deze zal opschalen, aangezien wordt aangenomen dat de markt voor gegevensetikettering een enorme waardering van $ 4.4 miljard zal bereiken. tegen 2023.
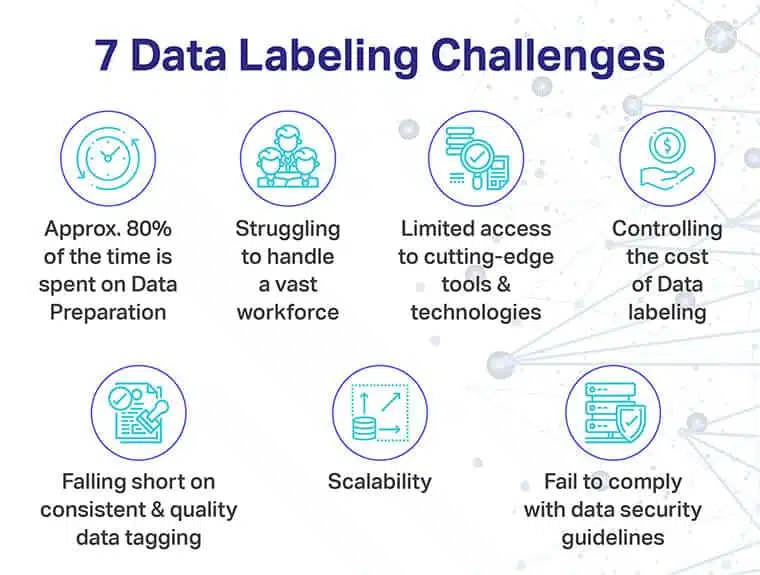
Het labelen van gegevens is de noodzaak van het uur, maar gaat gepaard met verschillende implementatie- en prijsspecifieke uitdagingen.
Enkele van de meer dringende zijn:
- Trage gegevensvoorbereiding dankzij redundante opschoningstools
- Gebrek aan vereiste hardware om een enorm personeelsbestand en een buitensporige hoeveelheid geschraapte gegevens aan te kunnen
- Beperkte toegang tot geavanceerde labeltools en ondersteunende technologieën
- Hogere kosten van gegevenslabels
- Gebrek aan consistentie als het gaat om kwaliteitsgegevenslabels
- Gebrek aan schaalbaarheid, of en wanneer het AI-model een extra set deelnemers moet dekken
- Gebrek aan naleving als het gaat om het handhaven van een stabiele houding op het gebied van gegevensbeveiliging tijdens het verkrijgen van gegevens en het gebruik ervan

Hoewel u datalabeling conceptueel kunt scheiden, vereisen de relevante tools dat u de concepten classificeert volgens de aard van de datasets. Waaronder:
- Audioclassificatie: Omvat audioverzameling, segmentatie en transcriptie
- Afbeelding labelen: Bestaande uit verzameling, classificatie, segmentatie en etikettering van belangrijke gegevens
- Tekstlabel: Omvat tekstextractie en classificatie
- Videolabels: Bevat elementen zoals videoverzameling, classificatie en segmentatie
- 3D-labeling: Functies voor het volgen en segmenteren van objecten
Afgezien van de bovengenoemde scheiding, vooral vanuit een breder perspectief, is gegevenslabeling onderverdeeld in vier typen, waaronder beschrijvend, evaluatief, informatief en combinatie. Classificatie, Extractie, Object Tracking, die we al hebben besproken voor de afzonderlijke datasets.

Het labelen van gegevens is een gedetailleerd proces en omvat de volgende stappen om AI-modellen categorisch te trainen:
- Verzamelen van datasets, via strategieën, dwz in-house, open source, leveranciers
- Gegevenssets labelen volgens Computer Vision, Deep learning en NLP-specifieke mogelijkheden
- Testen en evalueren van geproduceerde modellen om intelligentie te bepalen als onderdeel van implementatie
- Voldoen aan acceptabele modelkwaliteit en uiteindelijk vrijgeven voor uitgebreid gebruik

De juiste set tools voor het labelen van gegevens, synoniem voor een geloofwaardig platform voor het labelen van gegevens, moet worden geselecteerd met inachtneming van de volgende factoren:
- Type intelligentie dat u wilt dat het model heeft via gedefinieerde gebruiksscenario's
- Kwaliteit en ervaring van gegevensannotators, zodat ze de tools kunnen gebruiken voor precisie
- Kwaliteitsnormen die u in gedachten heeft
- Nalevingsspecifieke behoeften
- Commerciële, open-source en freeware-tools
- Budget dat u kunt missen
Naast de genoemde factoren kunt u beter rekening houden met de volgende overwegingen:
- Etiketteringsnauwkeurigheid van de gereedschappen
- Kwaliteitsborging wordt gegarandeerd door de tools
- Integratiemogelijkheden
- Beveiliging en immunisatie tegen lekken
- Cloudgebaseerde installatie of niet
- Kwaliteitscontrole management inzicht
- Fail-Safes, Stop-Gaps en schaalbare vaardigheden van de tool
- Het bedrijf dat de tools aanbiedt
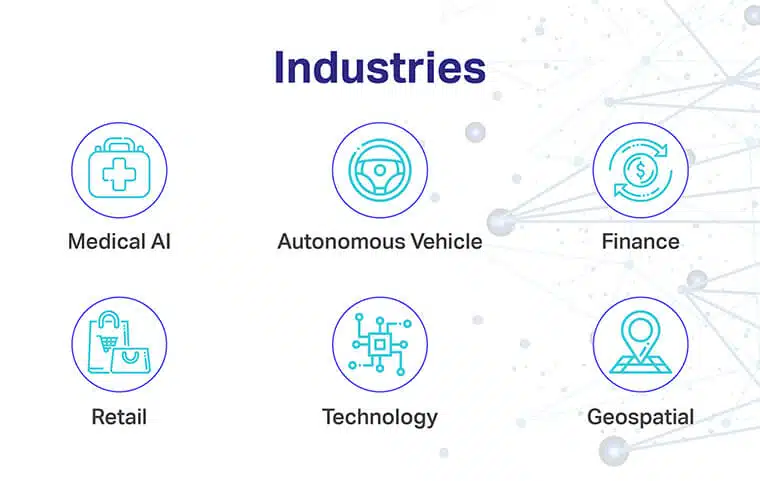
Verticalen die het best worden bediend door tools en bronnen voor gegevenslabeling zijn onder meer:
- Medische AI: Aandachtsgebieden zijn onder meer het trainen van diagnostische modellen met computervisie voor verbeterde medische beeldvorming, minimale wachttijden en minimale achterstand
- Financiën: Aandachtsgebieden zijn onder meer het evalueren van kredietrisico's, geschiktheid van leningen en andere belangrijke factoren via tekstlabels
- Autonoom voertuig of transport: Aandachtsgebieden zijn onder meer NLP en Computer Vision-implementatie om modellen te stapelen met een waanzinnige hoeveelheid trainingsgegevens voor het detecteren van individuen, signalen, blokkades, enz.
- Detailhandel en e-commerce: Aandachtsgebieden zijn onder meer prijsspecifieke beslissingen, verbeterde e-commerce, het bewaken van de persona van de koper, het begrijpen van koopgewoonten en het versterken van de gebruikerservaring
- Technologie: Aandachtsgebieden zijn onder meer productproductie, bin-picking, het vooraf detecteren van kritieke productiefouten en meer
- Geospatiaal: Aandachtsgebieden zijn onder meer GPS en remote sensing door geselecteerde labeltechnieken
- Landbouw: Aandachtsgebieden zijn onder meer het gebruik van GPS-sensoren, drones en computervisie om de concepten van precisielandbouw te bevorderen, bodem- en gewasomstandigheden te optimaliseren, opbrengsten te bepalen en meer

Nog steeds in de war over wat een betere strategie is om gegevenslabels op schema te krijgen, dat wil zeggen, een zelfbeheerde installatie bouwen of er een kopen bij een externe serviceprovider. Hier zijn de voor- en nadelen van elk om u te helpen een betere beslissing te nemen:
De 'Build'-aanpak
| Bouw | Kopen |
|---|---|
Hits:
| Hits:
|
Misses:
| Misses:
|
Voordelen:
| Voordelen:
|
Vonnis
Als u van plan bent een exclusief AI-systeem te bouwen zonder dat de tijd een beperking is, is het zinvol om vanaf het begin een labeltool te bouwen. Voor al het andere is het kopen van een tool de beste aanpak


