

De kwaliteit en nauwkeurigheid van de resultaten van een gezichts- en emotieherkenningssysteem zijn afhankelijk van de gegevens. Hoe nauwkeuriger en uitgebreider de gegevens zijn, hoe groter de kans dat een AI-programma emoties kan identificeren en detecteren.

Kunstmatige intelligentie heeft een aantal verstrekkende voordelen voor de verzekeringssector, op voorwaarde dat de bedrijven de implementatie ervan begrijpen. Waar taken als claimverwerking, premiestelling en schadedetectie worden gestroomlijnd, kan het ook helpen bij de klantenservice, waardoor het algehele tevredenheidsniveau toeneemt.

De-identificatie van gegevens is van cruciaal belang voor het beschermen van persoonlijk identificeerbare informatie in de gezondheidszorg, in overeenstemming met wettelijke vereisten zoals HIPAA en AVG. De aanbevolen tools, waaronder IBM InfoSphere Optim, Google Healthcare API, AWS Comprehend Medical, Shaip en Private-AI, bieden diverse oplossingen voor effectieve gegevensmaskering.

Generatieve AI heeft een aantal krachtige functies en functionaliteiten die zijn ingesteld om ondersteuningssystemen voor klantenservice te herzien. Waar het de problemen van de klant snel kan aanpakken, kan generatieve AI ook agenten als eerstehulpverleners vervangen en als een mens met klanten communiceren.

De-identificatie van gegevens is een cruciale procedure om de bescherming tegen ongeoorloofde toegang en onrechtmatig gebruik van persoonlijke gegevens te waarborgen. Dit proces is vooral belangrijk voor gezondheidszorggegevens en zorgt ervoor dat er geen persoonlijk identificeerbare informatie in handen komt van andere personen dan degenen die nauw verwant zijn aan de gegevens.

Conversationele en generatieve AI transformeren onze wereld op unieke manieren. Conversationele AI maakt praten met machines eenvoudig en nuttig, waardoor de klantenondersteuning en gezondheidszorgdiensten worden verbeterd. Generatieve AI is daarentegen een creatieve krachtpatser. Het bedenkt nieuwe, originele inhoud op het gebied van kunst, muziek en meer. Het begrijpen van deze AI-typen is de sleutel tot slimme zakelijke, ethische en innovatiebeslissingen.

Spraaktechnologieën zijn nog relatief nieuwe technologieën en we werken er nog steeds aan om een goed inzicht te krijgen in de oplossingen die daarmee worden geboden. In een tijdgevoelige gezondheidszorgomgeving zijn efficiëntie en nauwkeurigheid van het allergrootste belang.

Generatieve AI hervormt het landschap van bank- en financiële diensten, introduceert efficiëntie, verbetert de veiligheid en levert gepersonaliseerde ervaringen voor zowel klanten als instellingen. Naarmate de technologie zich blijft ontwikkelen, zal de impact ervan op de financiële sector waarschijnlijk toenemen, wat een nieuw tijdperk van innovatie en optimalisatie zal inluiden.

Het gebruik van Natural Language Processing (NLP) in de gezondheidszorg en de farmaceutische industrie is sterk gebaseerd op de analyse van ongestructureerde gegevens. Met relevante informatie kunnen zorgorganisaties verschillende voordelen behalen en betere gezondheidszorgdiensten aan patiënten leveren.

De hoeveelheid en frequentie van door gebruikers gegenereerde inhoud zal de komende jaren toenemen. Klanten hebben tegenwoordig toegang tot innovatieve tools, waardoor ze alles over een merk weten. Waar interactie met bestaande, nieuwe en potentiële klanten essentieel is voor een merk, is het monitoren en modereren van content cruciaal voor het creëren van een positief imago.

Effectieve gegevenslabeling is een cruciaal onderdeel van het verbeteren van de zoekrelevantie. E-commerceplatforms en bedrijven profiteren het meest van datalabeling, omdat ze hun producten in de zoekresultaten moeten weergeven, wat leidt tot een stijging van de omzet en inkomsten.

Natuurlijke taalverwerking (NLP) heeft in alle sectoren een revolutie op het gebied van informatie-extractie en -analyse op gang gebracht. De veelzijdigheid van deze technologie evolueert ook om betere oplossingen en nieuwe toepassingen te bieden. Het gebruik van NLP in de financiële wereld is niet beperkt tot de toepassingen die we hierboven hebben genoemd. Na verloop van tijd kunnen we deze technologie en de bijbehorende technieken gebruiken voor nog complexere taken en bewerkingen.

De kern van de toepassingen van AI in de gezondheidszorg zijn data en de juiste analyse ervan. Met behulp van deze gegevens en informatie van zorgprofessionals kunnen AI-hulpmiddelen en -technologieën betere gezondheidszorgoplossingen bieden op het gebied van diagnose, behandeling, voorspelling, voorschrijven en beeldvorming.

Herkenning van benoemde entiteiten is een essentiële techniek die de weg vrijmaakt voor geavanceerd machinaal begrip van de tekst. Hoewel open-source datasets voor- en nadelen hebben, spelen ze een belangrijke rol bij het trainen en verfijnen van NER-modellen. Een redelijke selectie en toepassing van deze middelen kan de resultaten van NLP-projecten aanzienlijk verbeteren.

Generatieve AI biedt opmerkelijke voordelen zoals efficiëntie, schaalbaarheid en personalisatie, dankzij het vermogen om diverse inhoud te creëren. Uitdagingen als kwaliteitscontrole, creativiteitsbeperkingen en ethische problemen vereisen echter zorgvuldige aandacht.

Generatieve AI is een opwindende grens die de grenzen van technologie en creativiteit opnieuw definieert. Van het genereren van mensachtige tekst tot het creëren van realistische afbeeldingen, het verbeteren van de codeontwikkeling en zelfs het simuleren van unieke audio-uitvoer: de toepassingen in de echte wereld zijn even divers als transformatief.

De toepassingen van machine learning en AI bij de analyse van klinische gegevens zijn uitgebreid en baanbrekend. Ze bieden een enorm potentieel voor het hervormen van de patiëntenzorg, het verbeteren van medisch onderzoek en het stellen van eerdere en nauwkeurigere diagnoses.

Shaip loopt voorop bij het leveren van eersteklas gezondheidszorg en medische gegevens die essentieel zijn voor AI- en machine learning (ML)-modellen. Als u aan een AI-project voor de gezondheidszorg begint of specifieke medische gegevens nodig heeft, is Shaip de perfecte partner.

Spraakassistenten zijn geen nieuwigheid meer; ze worden snel essentieel voor onze dagelijkse digitale interacties. De opkomst van de meertalige stemassistent belooft een grote stap voorwaarts te zijn, waarbij taalbarrières worden doorbroken en een grotere wereldwijde connectiviteit wordt bevorderd.
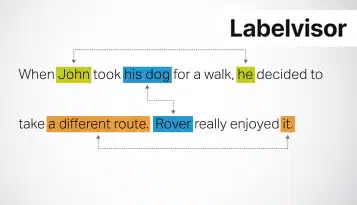
Documentannotatie is een essentiële bouwsteen in AI, machine learning en natuurlijke taalverwerking. Het verbetert het begrip en de verwerkingsmogelijkheden van AI-systemen, waardoor efficiënte informatie-extractie mogelijk wordt en automatisering in verschillende domeinen wordt bevorderd.

Zoals we in de bovenstaande voorbeelden hebben onderzocht, heeft sentimentanalyse een opmerkelijk potentieel in een verscheidenheid aan toepassingen, variërend van klantenservice tot politiek. Het stelt organisaties in staat om de kracht van subjectieve gegevens te ontsluiten en ongestructureerde tekst om te zetten in bruikbare inzichten.

De toekomst van AI in de gezondheidszorg is veelbelovend en potentieel, waarbij de opkomende trends voor 2023 een transformatieve verschuiving in de levering van patiëntenzorg signaleren.

De use cases van Natural Language Processing in de gezondheidszorg zijn enorm en transformerend. Door gebruik te maken van de kracht van AI, machine learning en conversationele AI, zorgt NLP voor een revolutie in de manier waarop zorgprofessionals patiëntenzorg benaderen. Het maakt medische workflows efficiënter en verbetert de algehele patiëntresultaten.
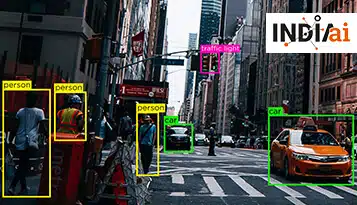
Het toepassen van op AI gebaseerde entiteitsextractie heeft geleid tot aanzienlijke vooruitgang in verschillende sectoren, van gezondheidszorg tot e-commerce, het verbeteren van de besluitvorming, het stroomlijnen van processen en het verbeteren van klantervaringen.

Emotieherkenningstechnologie is een krachtig hulpmiddel dat ons begrip van menselijke emoties kan vergroten en ons kan helpen gepersonaliseerde ervaringen te creëren in verschillende domeinen, zoals gezondheidszorg, onderwijs en marketing.

Al met al zit de gezondheidszorg vol met patiënten en artsen die gemotiveerd zijn om opnieuw een verschil te maken in het leven van mensen over de hele wereld. Toegang tot grote datasets is eenrichtingsverkeer. Kunstmatige intelligentie zal zichzelf blijven bewijzen als de toekomst van de geneeskunde. Het is aan zowel onderzoekers als ontwikkelaars om te profiteren van deze unieke datasets om ons begrip van klinische onderzoeken en patiëntenzorg te verbeteren terwijl we op weg zijn naar een steeds meer verbonden toekomst voor iedereen.

De komende vijf jaar zullen meer gestroomlijnde AI-ervaringen, beveiligingsfuncties die die interacties verbeteren, en meer brengen. Conversationele AI-trends zullen de komende jaren helderder en toegankelijker zijn dan ooit tevoren.

De veranderingen zijn aan de gang, wat leidt tot een meer betaalbare, winstgevende toekomst die een betere gebruikerservaring biedt. Met deze veranderingen in combinatie met het vermogen om te leren van de fouten van andere bedrijven, zal de BFSI-sector snel vooruitgang blijven boeken in de richting van het gebruik van gezichtsherkenning - een effectiever en veiliger einddoel voor alle betrokken instanties.

Gesproken zoekopdrachten zijn een snelgroeiend gebied van technologie. Het boekt langzaam maar zeker enorme vooruitgang naarmate het meer capabel wordt met AI, natuurlijke taalverwerking en machine learning. Het type AI dat nu bestaat, is niet bewust; deze stemassistenten zijn hulpmiddelen om ons leven beter, eenvoudiger en efficiënter te maken.
Gegevenslabelservices helpen bedrijven gegevens zonder labels of tags om te zetten in gegevens die dat wel hebben. Ze gebruiken vaak een menselijke taskforce of machine learning om de datasets te labelen die bedrijven hen geven.

Spraakherkenningstechnologie kan op verschillende manieren een revolutie teweegbrengen in de gezondheidszorg. Door snellere en nauwkeurigere documentatie mogelijk te maken, het risico op fouten te verkleinen en de betrokkenheid van de patiënt te verbeteren, kan spraakherkenningstechnologie zorgverleners helpen zorg van betere kwaliteit te bieden.

De verzekeringssector heeft veel gegevens, maar het is zo rommelig dat het bijna onmogelijk is om te zoeken. De verzekeringssector moet worden gedigitaliseerd - en dat kan nu. Met OCR wordt het verzamelen en sorteren van gegevens net zo eenvoudig als het maken van een foto of het typen van een paar woorden.

Banken zullen een positieve ervaring hebben bij het implementeren van AI-technologieën. Dit is gebaseerd op interviews met bedrijven die AI al toepassen in hun bedrijfsprocessen. Zolang er waarborgen zijn ingebouwd om de veiligheid van klantgegevens te waarborgen en ethische normen die automatisch kunnen worden gereguleerd, moeten banken AI in hun systemen implementeren.

De impact van machine learning in de callcentermarkt is reëel en meetbaar. Realtime gegevensverzameling en machine learning zijn gecombineerd om nog efficiëntere callcenters mogelijk te maken. Bovendien zijn spraakgebaseerde oplossingen in heel Noord-Amerika toegenomen en blijven ze zich over de hele wereld verspreiden.

Spraakherkenningstechnologie wordt steeds belangrijker in de gezondheidszorg, waarbij artsen en verpleegkundigen er steeds meer op vertrouwen om veel van hun professionele taken uit te voeren. Hoewel er nog veel vragen moeten worden beantwoord voordat we zien dat deze technologie op grote schaal wordt gebruikt in ziekenhuizen, klinische omgevingen en dokterspraktijken, wijzen de eerste tekenen op een grote belofte.
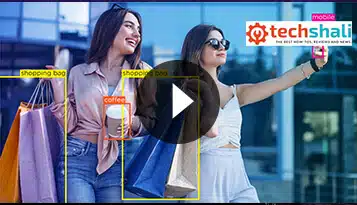
Video-annotatietechnologie is bedoeld om AI-systemen in de detailhandel en klanten veilig te houden. Video-annotatiesoftware is een geweldige manier om dit te doen door mensen snel en gemakkelijk autoriteiten te laten waarschuwen wanneer ze getuige zijn van iets verdachts in een winkelomgeving en; AI-systemen helpen te leren van ervaringen uit het verleden, zodat ze hun reacties kunnen aanpassen om zich beter te voelen over wat als normaal gedrag wordt beschouwd.

Gebruiksgevallen van gezichtsherkenning kunnen wonderen verrichten bij het opslaan en ophalen van gegevens, maar ze brengen ook een intrigerend ethisch dilemma met zich mee. Heeft het zin om een dergelijke technologie te gebruiken? Sommige mensen denken dat het antwoord "nee" is, vooral met betrekking tot de schending van de privacy door gezichtsherkenning. Anderen noemen het gebruik van deze nieuwe tools, en daarom is deze technologie misschien niet een die je ten koste van alles wilt vermijden.

AI zal de manier waarop we omgaan met technologie veranderen. Als je eenmaal gewend bent aan conversationele AI en het een naadloos onderdeel van je leven wordt, vraag je je af hoe je ooit zonder had gekund.

Aangepaste wake-words kunnen helpen bij de personalisatie van uw merk en het onderscheiden van concurrenten. Er zijn veel factoren waarmee u rekening moet houden bij het selecteren van een aangepast wake-word. Maar als u wilt opvallen in de competitieve zakenwereld van vandaag, is het de moeite waard om extra moeite te doen om ervoor te zorgen dat uw stemassistent uniek klinkt.

Nieuwe ontwikkelingen op het gebied van spraaktechnologie zijn er om te blijven. Ze zullen alleen maar in populariteit blijven groeien, waardoor dit het perfecte moment is om voorop te lopen en innovatieve spraakervaringen voor chauffeurs te creëren. Nu autofabrikanten spraakherkenning in hun auto's integreren, opent dit een nieuwe wereld van mogelijkheden voor de technologie en haar gebruikers.

Het is duidelijk dat voedsel-AI een enorme invloed zal hebben op hoe we eten. Van het streven van fastfoodketens naar meer aanpasbare menu's tot een hele reeks nieuwe, innovatieve restaurants, er zijn talloze kansen voor technologie om onze eetervaringen te vereenvoudigen en de kwaliteit van ons voedsel te verbeteren. Met de vooruitgang van kunstmatige intelligentie en machine learning-algoritmen kunnen we verwachten dat intelligente voedsel-AI een positieve invloed zal hebben op onze gezondheid en de algehele ecologische impact van ons voedselsysteem.

Samenvattend is semantische segmentatie een belangrijke sector van deep learning-algoritmen die worden gebruikt om de vooruitgang in computervisie te stimuleren. Semantische segmentatie zal zich blijven ontwikkelen in veel van deze gerelateerde subcategorieën, objectdetectie, classificatie en lokalisatie.

Over het algemeen moet een effectief spraakherkenningssysteem eenvoudig in te stellen en te gebruiken zijn in verschillende situaties, terwijl het nauwkeurige resultaten oplevert met weinig frustratie van de kant van de gebruiker.

Het bouwen van smart home-gegevens vereist een reeks processen die ervoor zorgen dat het machine learning-algoritme uiteindelijk werkt en gegevens verwerkt zonder enige onderbreking.

De verzekeringssector is traditioneel conservatief geweest met technologische vooruitgang en aarzelde om nieuwe technologieën toe te passen. De tijden veranderen echter en kunstmatige intelligentie (AI) krijgt veel aandacht van verzekeringsmaatschappijen, die de belangrijke rol beginnen te beseffen die AI kan spelen in hun bedrijfsvoering.

Gegevensverzameling is het proces van het verzamelen, analyseren en meten van nauwkeurige gegevens uit verschillende systemen om te gebruiken voor besluitvorming over bedrijfsprocessen, spraakprojecten en onderzoek.

Bankieren is niet meer wat het geweest is. De meesten van ons hebben snelle, efficiënte, foutloze bankdiensten nodig die probleemloos en vooral betrouwbaar zijn. Het is alleen maar logisch om over te schakelen naar digitale bankkanalen die deze dingen kunnen bieden. Het blijkt dat kunstmatige intelligentie (AI) en machine learning (ML) aangedreven virtuele assistenten precies dat kunnen.

Heb je ooit belangrijke e-mails in een andere taal moeten vertalen? Als dat zo is, zult u het frustrerend vinden om te weten dat iemands e-mailbeantwoordingsservice uw e-mails niet snel voor u kan vertalen. Dit kan vooral frustrerend zijn als communicatie essentieel is voor elke organisatie.

De termen chatbot en virtuele assistenten worden gebruikt voor het creëren van gesprekken met behulp van automatiseringsmogelijkheden met een menselijke aanraking. Met autonome resolutie versnellen chatbots en virtuele assistenten ook de werknemers- en klantervaring.

Vaak beschouwd als een van de subdomeinen van tekstclassificatie, betekent een te vereenvoudigde versie van documentclassificatie het taggen van de documenten en het plaatsen ervan in vooraf gedefinieerde categorieën - met het oog op eenvoudig onderhoud en efficiënte detectie.

Hé Siri, kun je me zoeken naar een goede blogpost met de beste Conversational AI-trends. Of, Alexa, kun je gewoon een nummer voor me spelen dat mijn gedachten afleidt van de alledaagse taken. Welnu, dit zijn niet alleen retoriek, maar standaard salondiscussies die de algehele impact valideren van een concept dat Conversational AI wordt genoemd.

OCR of Optical Character Recognition is een leuke manier om documenten te lezen en te begrijpen. Maar waarom heeft het überhaupt zin? Laten we het uitzoeken. Maar voordat we verder gaan, moeten we ons bezighouden met een minder gebruikelijke term voor machine learning: RPA (Robotic Process Automation).

De harde waarheid is dat de kwaliteit van uw verzamelde trainingsgegevens de kwaliteit van uw spraakherkenningsmodel of zelfs het apparaat bepaalt. Daarom is het noodzakelijk om contact te leggen met ervaren gegevensleveranciers om u te helpen het proces zonder veel moeite te doorlopen, vooral wanneer het trainen van een model of de betrokken algoritmen het verzamelen, annoteren en andere bekwame strategieën vereist.

Het vermogen dat in de machines is gegoten - waardoor ze in staat zijn om op de meest humane manieren met elkaar om te gaan - heeft een ander soort high. Maar de vraag blijft hoe conversatie-AI in realtime werkt en wat voor soort technologie het bestaan ervan aandrijft.

Zoals de naam al doet vermoeden, zijn synthetische gegevens de gegevens die kunstmatig worden gegenereerd in plaats van door feitelijke gebeurtenissen te worden gecreëerd. In marketing, sociale media, gezondheidszorg, financiën en beveiliging helpen synthetische gegevens bij het bouwen van meer innovatieve oplossingen.

Als we het hebben over Optical Character Recognition (OCR), is het een gebied van kunstmatige intelligentie (AI) dat specifiek gerelateerd is aan computervisie en patroonherkenning. OCR verwijst naar het proces van het extraheren van informatie uit meerdere gegevensformaten zoals afbeeldingen, pdf, handgeschreven notities en gescande documenten en deze om te zetten in een digitaal formaat voor verdere verwerking.

Het bestuurdersbewakingssysteem is een geavanceerde veiligheidsvoorziening die gebruik maakt van een camera die op het dashboard is gemonteerd om de alertheid en slaperigheid van de bestuurder te bewaken. Als de bestuurder slaperig en afgeleid wordt, genereert het monitoringsysteem van de bestuurder een waarschuwing en raadt hij aan een pauze te nemen.

Natuurlijke taalverwerking is een deelgebied van kunstmatige intelligentie dat in staat is om menselijke taal af te breken en de principes daarvan aan de intelligente modellen te geven. Ben je van plan om NLP als je modeltrainingstechnologie te gebruiken? Lees verder om de uitdagingen en oplossingen te kennen om ze op te lossen.

Bovendien leert Conversational AI voortdurend van eerdere ervaringen met behulp van machine learning-datasets om realtime inzicht en uitstekende klantenservice te bieden. Conversational AI begrijpt en reageert niet alleen handmatig op onze vragen, maar kan ook worden verbonden met andere AI-technologieën zoals zoeken en visie om het proces te versnellen.

Beeldherkenning is het vermogen van software om objecten, plaatsen, mensen en acties in afbeeldingen te identificeren. Met behulp van datasets voor machine learning kunnen bedrijven beeldherkenning gebruiken om objecten te identificeren en in te delen in verschillende categorieën.

Kunstmatige intelligentie maakt machines slimmer, punt uit! Toch is de manier waarop ze het doen net zo anders en intrigerend als de betreffende verticaal. Natural Language Processing is bijvoorbeeld handig als je slimme chatbots en digitale assistenten wilt ontwerpen en ontwikkelen. Evenzo, als u de verzekeringssector transparanter en accommoderender wilt maken voor de gebruikers, is Computer Vision het AI-subdomein waarop u zich moet concentreren.

Kunnen machines emoties detecteren door simpelweg het gezicht te scannen? Het goede nieuws is dat ze dat kunnen. En het slechte nieuws is dat de markt nog een lange weg te gaan heeft voordat het mainstream wordt. Toch weerhouden de wegversperringen en adoptie-uitdagingen de AI-evangelisten er niet van om 'Emotiedetectie' op de AI-kaart te zetten - behoorlijk agressief.

Computer Vision is niet zo wijdverbreid als andere AI-toepassingen zoals Natural Language Processing. Toch komt het langzaam in de gelederen, waardoor 2022 een opwindend jaar wordt voor grootschalige adoptie. Hier zijn enkele van de trendy mogelijkheden voor computervisie (meestal de domeinen) die naar verwachting in 2022 door bedrijven beter zullen worden verkend.

Bedrijven over de hele wereld stappen over van papieren documenten naar digitale gegevensverwerking. Maar wat is OCR? Hoe werkt het? En in welk bedrijfsproces kan het worden gebruikt om de voordelen ervan te benutten? Laten we in dit artikel ingaan op de voordelen die OCR met zich meebrengt.

Het antwoord is Automatische Spraakherkenning (ASR). Het is een enorme stap om het gesproken woord om te zetten in geschreven vorm. Automatische spraakherkenning (ASR) is een trend die in 2022 geluid gaat maken. En de toename van de groei van spraakassistenten is te danken aan ingebouwde spraakassistent-smartphones en slimme spraakapparaten zoals Alexa.
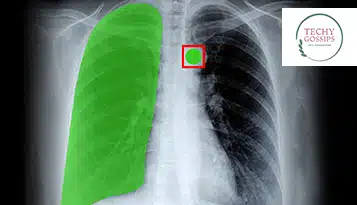
Ben je op zoek naar het brein achter de beste modellen voor kunstmatige intelligentie? Nou, buig voor de Data Annotators. Hoewel gegevensannotatie centraal staat bij het voorbereiden van bronnen die relevant zijn voor elke AI-gestuurde verticaal, zullen we het concept onderzoeken en meer leren over de hoofdrolspelers op het gebied van etikettering vanuit het perspectief van AI in de gezondheidszorg.

En vind je het niet fascinerend als shoppers de rekening bij het uitchecken betalen door alleen een gezicht te vertegenwoordigen, niet een kaart of portemonnee? Met gezichtsherkenning kunnen retailers de stemmingen en voorkeuren van shoppers analyseren op basis van hun eerdere aankopen.

Hoe kunnen financiële organisaties, met de toenemende digitale betalingen die over de hele wereld worden gedaan, zorgen voor maximale verkoopconversie en betalingsacceptatie, en de blootstelling aan risico's minimaliseren? Klinkt alarmerend? In de financiële sector die sterk afhankelijk is van gegevensverwerking en informatie, is het behoud van een marginale voorsprong en het begrijpen van de natuurlijke nuance van klanten vereist om tijdige oplossing te bieden, AI-gerelateerde technologie.

Drones zijn een levensvatbaar hulpmiddel voor het verzamelen van gegevens en bieden realtime informatie. Het gebruik van data-analyse maakt het inspecteren van bruggen, mijnbouw en weersvoorspellingen eenvoudiger.

Callcenter-sentimentanalyse is de verwerking van gegevens door de natuurlijke nuance van de klantcontext te identificeren en gegevens te analyseren om de klantenservice empathischer te maken.

Nou, de eerste reden heeft geen validatie nodig. Machine learning-projecten vereisen dat algoritmen, gegevensinkoop, hoogwaardige annotaties en andere complexe aspecten goed worden geregeld.

Als tak van kunstmatige intelligentie draait het bij NLP om het maken van machines die reageren op menselijke taal. Wat betreft het technische aspect, NLP gebruikt, heel toepasselijk, computerwetenschap, taalkunde, algoritmen en de algemene taalstructuur om de machines intelligent te maken. De proactieve en intuïtieve machines kunnen, wanneer gebouwd, de ware betekenis en context uit spraak en zelfs tekst extraheren, analyseren en begrijpen.

Dit is waar medische beeldannotatie een rol te spelen heeft, omdat het op efficiënte wijze de vereiste kennis overbrengt aan de door AI aangedreven medische diagnostische opstellingen voor het bevorderen van de aanwezigheid van nauwkeurige computervisie, als de onderliggende modelontwikkelingstechnologie.

Kunstmatige intelligentie hoeft geen grimmig onderwerp te zijn om te bespreken. Vol met mogelijkheden om de komende jaren het meest transformatieve hulpmiddel te worden, wordt AI snel een hulpmiddel in plaats van op koers te blijven als een overweldigende technologie.

Bent u zich bewust van de technische aspecten die komen kijken bij het holistisch, intuïtief en impactvol maken van Machine Learning-modellen? Als dat niet het geval is, moet u eerst begrijpen hoe elk proces in grote lijnen is onderverdeeld in drie fasen, namelijk Fun, Functionaliteit en Finesse. Terwijl de 'Finesse' gaat over het tot in de perfectie trainen van ML-algoritmen door eerst complexe programma's te ontwikkelen met behulp van relevante programmeertalen, gaat het 'Fun'-gedeelte over het tevreden maken van de klanten door hen het opmerkzame en intelligente plezierproduct aan te bieden.

Stel je voor dat je op een mooie dag wakker wordt en al je keukencontainers in het zwart ziet en je verblindt voor wat erin zit. En dan wordt het een uitdaging om suikerklontjes voor je thee te vinden. Mits je de thee als eerste kunt vinden.

Gegevensannotatie is eenvoudigweg het proces van het labelen van informatie zodat machines deze kunnen gebruiken. Het is vooral handig voor gesuperviseerde machine learning (ML), waarbij het systeem vertrouwt op gelabelde datasets om invoerpatronen te verwerken, te begrijpen en ervan te leren om tot de gewenste output te komen.

Data labelen is niet zo moeilijk, zei geen enkele organisatie ooit! Maar ondanks de uitdagingen onderweg, begrijpen niet veel mensen de veeleisende aard van de taken die voorhanden zijn. Het labelen van datasets, vooral om ze geschikt te maken voor AI- en Machine learning-modellen, vereist jarenlange ervaring en hands-on geloofwaardigheid. En als klap op de vuurpijl is het labelen van gegevens geen eendimensionale benadering en varieert het afhankelijk van het type model in de maak.

Het verkrijgen van gegevens voor spraakprojecten wordt vereenvoudigd wanneer u een systematische aanpak kiest. Lees onze exclusieve post over data-acquisitie voor spraakprojecten en krijg duidelijkheid.

In eenvoudige bewoordingen gaat het bij tekstannotaties om het labelen van specifieke documenten, digitale bestanden en zelfs de bijbehorende inhoud. Zodra deze bronnen zijn getagd of gelabeld, worden ze begrijpelijk en kunnen ze worden ingezet door de machine learning-algoritmen om de modellen tot in de perfectie te trainen.

Vandaag hebben we Vatsal Ghiya geselecteerd om zijn interview af te nemen. Vatsal Ghiya is een serieel ondernemer met meer dan 20 jaar ervaring in AI-software en -diensten in de gezondheidszorg. Hij is de CEO en mede-oprichter van Shaip, dat de on-demand schaling van ons platform, onze processen en mensen mogelijk maakt voor bedrijven met de meest veeleisende initiatieven op het gebied van machine learning en kunstmatige intelligentie.

Financiële diensten hebben in de loop van de tijd een metamorfose ondergaan. De golf van mobiele betalingen, persoonlijke bankoplossingen, betere kredietbewaking en andere financiële patronen zorgen er verder voor dat het domein van monetaire inclusies niet meer is wat het een paar jaar geleden was. In 2021 gaat het niet alleen om de 'Fin' of Finance, maar om alle 'FinTech' met disruptieve financiële technologieën die hun aanwezigheid laten voelen om de klantervaring, modus operandi voor relevante organisaties, of de hele fiscale arena om precies te zijn, te veranderen.
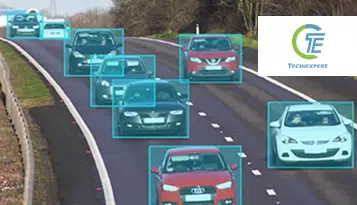
Ondanks de tijdige opkomst van de auto-industrie, laat de verticale sector veel ruimte voor stapsgewijze verbeteringen. Beginnend met het verminderen van verkeersongevallen tot het verbeteren van de productie van voertuigen en de inzet van middelen, lijkt kunstmatige intelligentie de meest waarschijnlijke oplossing om dingen in beweging te krijgen.

Kunstmatige intelligentie lijkt tegenwoordig meer op marketingjargon. Elk bedrijf, elke startup of elk bedrijf dat u kent, promoot zijn producten en diensten nu met de term 'AI-powered' als USP. In overeenstemming hiermee lijkt kunstmatige intelligentie tegenwoordig onvermijdelijk te zijn. Als je merkt dat bijna alles wat je om je heen hebt, wordt aangedreven door AI. Van de aanbevelingsengines op Netflix en algoritmen in dating-apps tot enkele van de meest complexe entiteiten in de zorgsector die helpen bij oncologie, kunstmatige intelligentie staat tegenwoordig aan de basis van alles.

Machine learning heeft waarschijnlijk de meest gemengde definities en interpretaties ter wereld. Wat een paar jaar geleden als een modewoord arriveerde, blijft veel mensen verbijsteren dankzij de manier waarop het is afgebeeld en gepresenteerd.

Kunstmatige intelligentie (AI) is ambitieus en enorm gunstig voor de vooruitgang van de mensheid. Vooral in een ruimte als de gezondheidszorg brengt kunstmatige intelligentie opmerkelijke veranderingen teweeg in de manier waarop we de diagnose van ziekten, hun behandelingen, patiëntenzorg en patiëntbewaking benaderen. Niet te vergeten het onderzoek en de ontwikkeling die betrokken zijn bij de ontwikkeling van nieuwe medicijnen, nieuwere manieren om zorgen en onderliggende aandoeningen te ontdekken, en meer.

Gezondheidszorg, als een verticaal, was nooit statisch. Maar ja, het is nog nooit zo dynamisch geweest, met de samenvloeiing van ongelijksoortige medische inzichten, waardoor we levenloos staren naar stapels ongestructureerde gegevens. Om eerlijk te zijn, de gigantische hoeveelheid gegevens is niet eens meer een probleem. Het is een realiteit, die eind 2,000 zelfs de grens van 2020 Exabyte overschreed.

Kunstmatige intelligentie is de technologie die machines in staat stelt om menselijk gedrag na te bootsen. Het gaat erom machines te leren autonoom te leren en te denken en de resultaten te gebruiken om dienovereenkomstig te reageren en te reageren.

Elke keer dat uw GPS-navigatiesysteem u vraagt om een omweg te maken om verkeer te vermijden, moet u zich realiseren dat zulke nauwkeurige analyses en resultaten na honderden uren training komen. Wanneer uw Google Lens-app een object of product nauwkeurig identificeert, moet u begrijpen dat duizenden en duizenden afbeeldingen zijn verwerkt door de AI-module (Artificial Intelligence) voor exacte identificatie.

4 basisdingen die u moet weten over de-identificatie van gegevens. Omdat er elke dag gegevens worden gegenereerd met een snelheid van 2.5 triljoen bytes, hebben wij als internetgebruikers in 1.7 bijna 2020 MB per seconde gegenereerd.

Nu de hele planeet online en verbonden is, genereren we collectief onmetelijke hoeveelheden data. Een bedrijfstak, een bedrijf, een marktsegment of een andere entiteit zou gegevens als een enkele eenheid beschouwen. Toch worden data wat individuen betreft beter onze digitale voetafdruk genoemd.

Kwaliteitsgegevens vertalen zich in succesverhalen, terwijl een slechte gegevenskwaliteit zorgt voor een goede case study. Enkele van de meest impactvolle casestudy's over AI-functionaliteit zijn voortgekomen uit een gebrek aan hoogwaardige datasets. Hoewel bedrijven allemaal enthousiast en ambitieus zijn over hun AI-ondernemingen en producten, weerspiegelt de opwinding niet de gegevensverzameling en trainingspraktijken. Met meer focus op output dan training, vertragen verschillende bedrijven hun time-to-market, verliezen ze financiering of trekken ze zelfs voor altijd hun luiken naar beneden.

Een proces om gegenereerde gegevens te annoteren of te taggen, waardoor algoritmen voor machine learning en kunstmatige intelligentie elk gegevenstype efficiënt kunnen identificeren en beslissen wat ervan te leren en wat ermee te doen. Hoe beter gedefinieerd of gelabeld elke dataset is, hoe beter de algoritmen deze kunnen verwerken voor optimale resultaten.
Alexa, is er een sushirestaurant bij mij in de buurt? Vaak stellen we open vragen aan onze virtuele assistenten. Het is begrijpelijk om dit soort vragen aan medemensen te stellen, aangezien we zo gewend zijn te spreken en met elkaar om te gaan. Het heeft echter geen enkele zin om een heel gewone vraag te stellen aan een machine die nauwelijks verstand heeft van taal en conversaties, toch?

Welnu, achter elk zo'n verrassend incident zijn er concepten in actie zoals kunstmatige intelligentie, machine learning en vooral NLP (Natural Language Processing). Een van de grootste doorbraken van onze laatste tijd is NLP, waar machines geleidelijk evolueren om te begrijpen hoe mensen praten, emote, begrijpen, reageren, analyseren en zelfs menselijke gesprekken en sentimentgedreven gedrag nabootsen. Dit concept is van grote invloed geweest op de ontwikkeling van chatbots, tekst-naar-spraak-tools, spraakherkenning, virtuele assistenten en meer.

Ondanks dat het een concept was dat in de jaren vijftig werd geïntroduceerd, werd kunstmatige intelligentie (AI) pas een paar jaar geleden een begrip. De evolutie van AI is geleidelijk gegaan en het heeft bijna 1950 decennia geduurd om de krankzinnige functies en functionaliteiten te bieden die het vandaag de dag biedt. Dit alles is enorm mogelijk geweest dankzij de gelijktijdige evolutie van hardware-randapparatuur, technische infrastructuren, aanverwante concepten zoals cloud computing, gegevensopslag- en verwerkingssystemen (Big Data en analyse), de penetratie en commercialisering van internet en meer. Alles bij elkaar heeft geleid tot deze verbazingwekkende fase van de technische tijdlijn, waarin AI en Machine Learning (ML) niet alleen innovaties aandrijven, maar ook onvermijdelijke concepten worden om zonder te leven.

Elk AI-systeem heeft enorme hoeveelheden kwaliteitsgegevens nodig om te trainen en nauwkeurige resultaten te leveren. Nu zijn er twee sleutelwoorden in deze zin: enorme volumes en kwaliteitsgegevens. Laten we beide afzonderlijk bespreken.

Alle gesprekken en discussies tot nu toe over de inzet van kunstmatige intelligentie voor zakelijke en operationele doeleinden waren slechts oppervlakkig. Sommigen praten over de voordelen van het implementeren ervan, terwijl anderen bespreken hoe een AI-module de productiviteit met 40% kan verhogen. Maar we pakken nauwelijks de echte uitdagingen aan die gepaard gaan met het opnemen ervan voor onze zakelijke doeleinden.
Het is moeilijk voorstelbaar om een wereldwijde pandemie te bestrijden zonder technologieën zoals kunstmatige intelligentie (AI) en machine learning (ML). De exponentiële toename van Covid-19-gevallen over de hele wereld heeft veel gezondheidsinfrastructuren verlamd. Instellingen, overheden en organisaties konden echter terugvechten met behulp van geavanceerde technologieën. Kunstmatige intelligentie en machine learning, ooit gezien als een luxe voor een verhoogde levensstijl en productiviteit, zijn dankzij hun ontelbare toepassingen levensreddende middelen geworden in de strijd tegen Covid.

Bij bepaalde groepen mensen wordt pijn intenser ervaren. Studies hebben aangetoond dat individuen uit minderheids- en kansarme groepen meer fysieke pijn ervaren dan de algemene bevolking als gevolg van stress, algehele gezondheid en andere factoren.

Voordat u zelfs maar van plan bent de gegevens aan te schaffen, is dit een van de belangrijkste overwegingen bij het bepalen hoeveel u aan uw AI-trainingsgegevens moet uitgeven. In dit artikel geven we je inzichten om een effectief budget voor AI-trainingsdata te ontwikkelen.

Shaip is een online platform dat zich richt op AI-gegevensoplossingen voor de gezondheidszorg en gelicentieerde zorggegevens biedt die zijn ontworpen om AI-modellen te helpen bouwen. Het biedt op tekst gebaseerde medische dossiers en claimgegevens van patiënten, audio zoals opnames van artsen of gesprekken tussen patiënt en arts, en afbeeldingen en video in de vorm van röntgenfoto's, CT-scans en MRI-resultaten.

Data is een van de belangrijkste elementen bij het ontwikkelen van een AI-algoritme. Onthoud dat het feit dat gegevens sneller dan ooit tevoren worden gegenereerd, niet betekent dat u gemakkelijk aan de juiste gegevens kunt komen. Gegevens van lage kwaliteit, vooringenomenheid of onjuist geannoteerde gegevens kunnen (op zijn best) nog een stap toevoegen. Deze extra stappen vertragen je omdat de data science- en ontwikkelteams deze moeten doorlopen op weg naar een functionele applicatie.

Er is veel gezegd over het potentieel van kunstmatige intelligentie om de gezondheidszorg te transformeren, en terecht. Geavanceerde AI-platforms worden gevoed door data, en zorgorganisaties hebben die in overvloed. Dus waarom is de industrie achtergebleven bij anderen op het gebied van AI-adoptie? Dat is een veelzijdige vraag met veel mogelijke antwoorden. Allemaal zullen ze echter ongetwijfeld één obstakel in het bijzonder naar voren brengen: grote hoeveelheden ongestructureerde data.

Wat echter eenvoudig lijkt, is vervelend om te ontwikkelen en in te zetten zoals elk ander complex AI-systeem. Voordat uw apparaat de afbeelding die u vastlegt kon herkennen en de Machine Learning (ML) -modules deze konden verwerken, zou een gegevensannotator of een team van hen duizenden uren hebben besteed aan het annoteren van gegevens om ze begrijpelijk te maken voor machines.

In deze speciale gastfunctie onderzoekt Vatsal Ghiya, CEO en mede-oprichter van Shaip, de drie factoren die volgens hem datagestuurde AI in de toekomst in staat zullen stellen zijn volledige potentieel te bereiken: het talent en de middelen die nodig zijn om innovatieve algoritmen te bouwen, een enorme hoeveelheid gegevens om die algoritmen nauwkeurig te trainen, en voldoende verwerkingskracht om die gegevens effectief te ontginnen. Vatsal is een serie-ondernemer met meer dan 20 jaar ervaring in AI-software en -diensten in de gezondheidszorg. Shaip maakt de on-demand schaling van zijn platform, processen en mensen mogelijk voor bedrijven met de meest veeleisende initiatieven op het gebied van machine learning en kunstmatige intelligentie.

Processen in kunstmatige intelligentie (AI)-systemen zijn evolutionair. In tegenstelling tot andere producten, diensten of systemen op de markt, bieden AI-modellen geen instant use cases of onmiddellijk 100% nauwkeurige resultaten. De resultaten evolueren met meer verwerking van relevante en kwaliteitsgegevens. Het is net als hoe een baby leert praten of hoe een muzikant begint met het leren van de eerste vijf majeurakkoorden en daarop voortbouwt. Prestaties worden niet van de ene op de andere dag ontgrendeld, maar er wordt consequent getraind voor uitmuntendheid.

Wanneer we het hebben over kunstmatige intelligentie (AI) en machine learning (ML), stellen we ons meteen krachtige technologiebedrijven, handige en futuristische oplossingen, mooie zelfrijdende auto's en eigenlijk alles voor wat esthetisch, creatief en intellectueel aantrekkelijk is. Wat nauwelijks op mensen wordt geprojecteerd, is de echte wereld achter alle gemakken en lifestyle-ervaringen die AI biedt.

Een exclusief interview waarin Utsav, Business Head - Shaip samenwerkt met Sunil, Executive Editor, My Startup om hem te informeren over hoe Shaip het menselijk leven verbetert door de problemen van de toekomst op te lossen met zijn Conversational AI en Healthcare AI-aanbiedingen. Hij stelt verder hoe AI en ML een revolutie teweeg zullen brengen in de manier waarop we zaken doen en hoe Shaip zal bijdragen aan de ontwikkeling van technologieën van de volgende generatie.
Kunstmatige intelligentie (AI) maakt onze levensstijl beter door betere filmaanbevelingen, restaurantsuggesties, het oplossen van conflicten via chatbots en meer. De kracht, het potentieel en de mogelijkheden van AI worden in toenemende mate goed gebruikt in verschillende sectoren en op gebieden waar waarschijnlijk niemand aan gedacht heeft. In feite wordt AI onderzocht en geïmplementeerd in gebieden zoals gezondheidszorg, detailhandel, bankwezen, strafrecht, toezicht, aanwerving, loonkloof oplossen en meer.

We hebben allemaal gezien wat er gebeurt als de ontwikkeling van AI misgaat. Denk aan de poging van Amazon om een AI-wervingssysteem te creëren, wat een geweldige manier was om cv's te scannen en de meest gekwalificeerde kandidaten te identificeren - op voorwaarde dat die kandidaten mannelijk waren.

De zorgsector werd vorig jaar door de pandemie op de proef gesteld en er kwam veel innovatie door - van nieuwe medicijnen en medische apparaten tot doorbraken in de toeleveringsketen en betere samenwerkingsprocessen. Bedrijfsleiders uit alle delen van de industrie hebben nieuwe manieren gevonden om de groei te versnellen om het algemeen welzijn te ondersteunen en cruciale inkomsten te genereren.

We hebben ze in films gezien, we hebben erover gelezen in boeken en we hebben ze in het echt meegemaakt. Hoe sci-fi het ook mag lijken, we moeten de feiten onder ogen zien - gezichtsherkenning is hier om te blijven. De technologie evolueert in een dynamisch tempo en met de uiteenlopende gebruiksscenario's die in verschillende sectoren opduiken, lijkt het brede scala aan ontwikkelingen op het gebied van gezichtsherkenning gewoon onvermijdelijk en oneindig.

Meertalige chatbots transformeren de zakenwereld. Chatbots hebben een lange weg afgelegd sinds hun vroege stadia, waar ze eenvoudige antwoorden van één woord zouden geven. Een chatbot kan nu vloeiend chatten in tientallen talen, waardoor bedrijven kunnen uitbreiden naar een grotere wereldwijde markt.

De gezondheidszorg wordt vaak gezien als een sector op het snijvlak van technologische innovatie. Dat is in veel opzichten waar, maar de gezondheidszorg is ook sterk gereguleerd door ingrijpende wetgeving zoals AVG en HIPAA, samen met nog veel meer lokale richtlijnen en beperkingen.

Een rapport uit 2018 onthulde dat we elke dag bijna 2.5 triljoen bytes aan gegevens hebben gegenereerd. In tegenstelling tot wat vaak wordt gedacht, kunnen niet alle gegevens die we genereren voor inzichten worden verwerkt.

Kunstmatige intelligentie wordt met de dag slimmer. Tegenwoordig zijn krachtige algoritmen voor machine learning binnen het bereik van normale bedrijven, en algoritmen die verwerkingskracht vereisen die ooit was gereserveerd voor massieve mainframes, kunnen nu worden ingezet op betaalbare cloudservers.