

Persoonlijk identificeerbare informatie (PII)
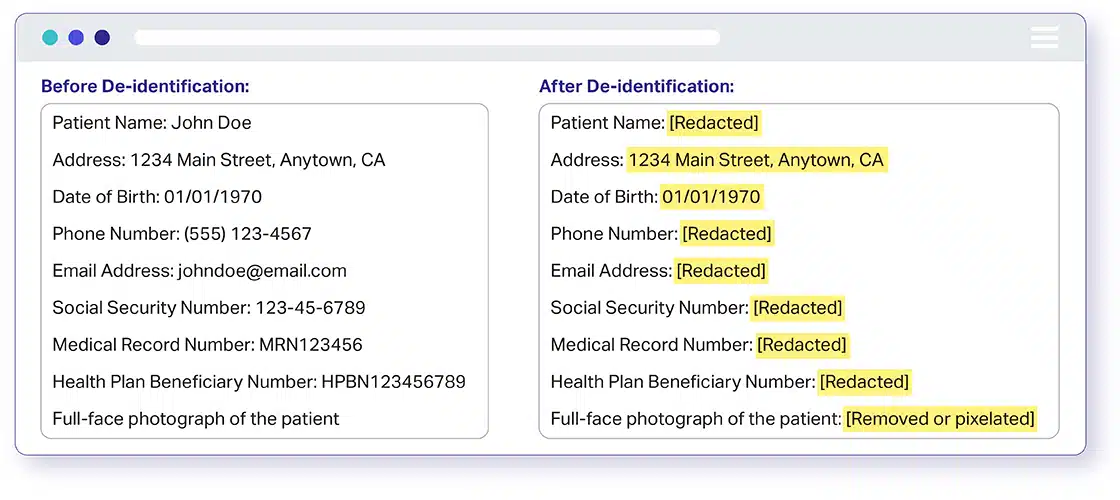
De-identificatie van PII-gegevens of anonimisering van PII-gegevens is het proces van het de-identificeren van alle informatie die de identiteit mogelijk maakt van een persoon op wie de geïdentificeerde informatie van toepassing is of redelijkerwijs kan worden afgeleid door directe of indirecte middelen. Kortom, persoonlijk identificeerbare informatie (PII) is alle gegevens die contact kunnen maken met een specifieke persoon, deze kunnen lokaliseren of identificeren.
Enkele van de HIPAA-de-identificatiestandaard-ID's of gegevenselementen die kunnen worden gebruikt om een persoon te identificeren, zijn onder meer:
| PII omvat: naam, e-mailadres, thuisadres, telefoonnummer | |
|---|---|
| Indien standalone | Indien gekoppeld met een andere identificatie |
| Burgerservicenummer | Staatsburgerschap of immigratiestatus |
| Rijbewijs of staats-ID | Meisjesnaam |
| Paspoortnummer | Etnische of religieuze overtuiging |
| Alien registratie nummer | seksuele geaardheid |
| Financieel rekeningnummer | Accountwachtwoorden |
| Biometrische identificatiegegevens | Laatste 4 cijfers van BSN |
| Telefoonnummers | Geboortedatum |
| E-mailadressen | criminele geschiedenis |
| Volledige gezichtsfoto's | |
Beschermde gezondheidsinformatie (PHI)
PHI Data De-identificatie of PHI Data Anonimisering is het proces van de-identificatie van alle informatie in een medisch dossier die kan worden gebruikt om een persoon te identificeren; die is gemaakt, gebruikt of openbaar gemaakt tijdens het verlenen van een medische dienst, zoals een diagnose of behandeling. In het kort is Protected Health Information (PHI) alle gegevens die contact kunnen maken met een specifieke persoon, deze kunnen lokaliseren of identificeren.
Enkele van de HIPAA-ID's of gegevenselementen die kunnen worden gebruikt om een persoon te identificeren, zijn onder meer:
- Medische beelden, dossiers, begunstigde van het gezondheidsplan, certificaat, sociale zekerheid en rekeningnummers
- Verleden, huidige of toekomstige gezondheid of toestand van een persoon
- Vroegere, huidige of toekomstige betaling voor het verlenen van gezondheidszorg aan een individu
- Elke datum die direct aan een persoon is gekoppeld, zoals geboortedatum, ontslagdatum, overlijdensdatum en administratie



Mensen
Toegewijde en getrainde teams:
- 30,000+ medewerkers voor gegevenscreatie, labeling en QA
- Gecertificeerd projectmanagementteam
- Ervaren productontwikkelingsteam
- Talentpool Sourcing & Onboarding-team

Proces
De hoogste procesefficiëntie wordt gegarandeerd met:
- Robuust 6 Sigma Stage-Gate-proces
- Een toegewijd team van 6 Sigma black belts – Key process owners & Quality compliance
- Continue verbetering en feedbacklus

Platform
Het gepatenteerde platform biedt voordelen:
- Webgebaseerd end-to-end platform
- Onberispelijke kwaliteit
- Snellere TAT
- Naadloze levering
Mensen
Toegewijde en getrainde teams:
- 30,000+ medewerkers voor gegevenscreatie, labeling en QA
- Gecertificeerd projectmanagementteam
- Ervaren productontwikkelingsteam
- Talentpool Sourcing & Onboarding-team
Proces
De hoogste procesefficiëntie wordt gegarandeerd met:
- Robuust 6 Sigma Stage-Gate-proces
- Een toegewijd team van 6 Sigma black belts – Key process owners & Quality compliance
- Continue verbetering en feedbacklus
Platform
Het gepatenteerde platform biedt voordelen:
- Webgebaseerd end-to-end platform
- Onberispelijke kwaliteit
- Snellere TAT
- Naadloze levering


