

Tekstclassificatie
De meest elementaire benadering met betrekking tot tekstannotatie, die zich richt op het categoriseren van tekst op basis van het inhoudstype, de intentie, het sentiment en het onderwerp. Eenmaal gecategoriseerd, worden de datasets in het systeem ingevoerd als onderdeel van een vooraf gedefinieerd segment, waartoe machines toegang hebben om een reactie te genereren
Taalkundige annotatie
Oorspronkelijk genoemd als corpusannotatie, richt deze vorm van tekstuele datasetlabels zich op de taaldetails van audio en teksten; Bovendien zijn er ook fonetische annotaties, stukjes semantische annotatie, POS-tagging, enz. nodig. Deze benadering is relevant als het gaat om het trainen van machinevertaalmodellen

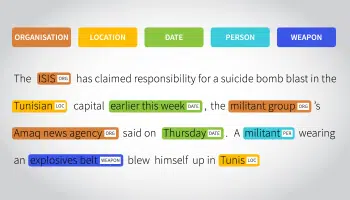
Entiteit annotatie
Deze methode van labelen is cruciaal als het gaat om Chatbot-training. De focus ligt hier op het extraheren, lokaliseren en taggen van entiteiten voordat de gegevens in het systeem worden ingevoerd. Zoals bij elke door Chatbot aangedreven interface, worden naamentiteiten, sleutelzinnen en POS-achtige bijvoeglijke naamwoorden, bijwoorden en meer het middelpunt.

Entiteit koppelen
Terwijl annotators entiteiten extraheren uit grotere gegevensopslagplaatsen, moeten ze met elkaar worden verbonden om gegevenssets te vormen die betekenis hebben. Dit is een van de weinige tekstannotatietools die het opzetten van volledige kennisdatabases omvat via ondubbelzinnigheid en uiteindelijk end-to-end-koppeling. bijv. URL-routering, rechtstreeks vanuit de chatinterface

SAO (Onderwerp Actie Object)
Wanneer een tekst meerdere entiteiten bevat, gekoppeld door een actie. Zo staat 'John hits Jimmy' open voor annotatie van entiteiten en tekstclassificatie, waarbij een label met betrekking tot op wet gebaseerde discussie wordt toegevoegd. Om het model echter de zin te laten begrijpen, moeten SAO-gegevens worden ingevoerd, waarbij John het onderwerp is, Jimmy het object en aanklagen als de actie.
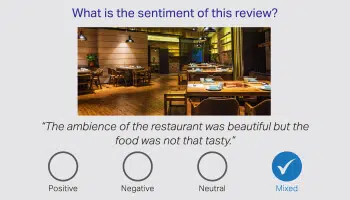
Sentimentannotatie
Sentimentannotatie zorgt voor emotionele labeling en maakt intelligente instellingen mogelijk om verborgen connotaties, meningen en specifieke sentimenten te detecteren. Annotators krijgen verantwoordelijkheden toegewezen om tekst te beoordelen en deze te labelen als negatief, neutraal en positief. Terwijl intentie annotatie zich richt op de wens van de vraag.

Mensen
Toegewijde en getrainde teams:
- 30,000+ medewerkers voor gegevenscreatie, labeling en QA
- Gecertificeerd projectmanagementteam
- Ervaren productontwikkelingsteam
- Talentpool Sourcing & Onboarding-team

Proces
De hoogste procesefficiëntie wordt gegarandeerd met:
- Robuust 6 Sigma Stage-Gate-proces
- Een toegewijd team van 6 Sigma black belts – Key process owners & Quality compliance
- Continue verbetering en feedbacklus

Platform
Het gepatenteerde platform biedt voordelen:
- Webgebaseerd end-to-end platform
- Onberispelijke kwaliteit
- Snellere TAT
- Naadloze levering
Mensen
Toegewijde en getrainde teams:
- 30,000+ medewerkers voor gegevenscreatie, labeling en QA
- Gecertificeerd projectmanagementteam
- Ervaren productontwikkelingsteam
- Talentpool Sourcing & Onboarding-team
Proces
De hoogste procesefficiëntie wordt gegarandeerd met:
- Robuust 6 Sigma Stage-Gate-proces
- Een toegewijd team van 6 Sigma black belts – Key process owners & Quality compliance
- Continue verbetering en feedbacklus
Platform
Het gepatenteerde platform biedt voordelen:
- Webgebaseerd end-to-end platform
- Onberispelijke kwaliteit
- Snellere TAT
- Naadloze levering
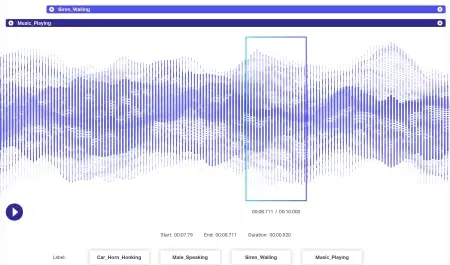
Audio-annotatie
Diensten
Het labelen van audiobronnen, spraak en stemspecifieke datasets via relevante tools zoals spraakherkenning, spreker diarisatie, emotieherkenning en meer, is iets waarin Shaip gespecialiseerd is.

Annotatie afbeelding
Diensten
We zijn trots op het labelen van gesegmenteerde beelddatasets om veeleisende computervisiemodellen te trainen. Enkele van de relevante technieken zijn grensherkenning en beeldclassificatie.

Videoannotatie
Diensten
Shaip biedt hoogwaardige videolabelservices voor het trainen van Computer Vision-modellen. Het doel hier is om datasets bruikbaar te maken met tools als patroonherkenning, objectdetectie en meer.


