



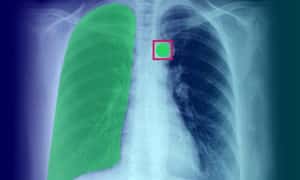
Medische beeldannotatie: definitie, toepassing, gebruiksscenario's en typen
Medische beeldannotatie speelt een cruciale rol bij het voorzien van machine learning-algoritmen en AI-modellen van de nodige trainingsgegevens. Dit proces is essentieel voor

Ethiek en vooringenomenheid: navigeren door de uitdagingen van de samenwerking tussen mens en AI bij modelevaluatie
In de zoektocht om de transformerende kracht van kunstmatige intelligentie (AI) te benutten, staat de technologiegemeenschap voor een cruciale uitdaging: het waarborgen van ethische integriteit en het minimaliseren van vooroordelen

The Human Touch: AI-creativiteit verbeteren met subjectieve evaluatie
In de snel evoluerende wereld van kunstmatige intelligentie (AI) is de zoektocht naar creativiteit niet langer alleen een menselijke onderneming. De huidige AI-technologieën zijn aan het breken

Zoekrelevantie maximaliseren met gegevenslabeling: tips en best practices
Gebruikers worden tegenwoordig ondergedompeld in enorme hoeveelheden informatie, wat het vinden van de informatie die ze nodig hebben complex maakt. Zoekrelevantie meet de nauwkeurigheid van informatie

De kloof overbruggen: menselijke intuïtie integreren in de evaluatie van AI-modellen
Inleiding In een tijdperk waarin kunstmatige intelligentie (AI) elk facet van ons leven vormgeeft, komt de integratie van menselijke intuïtie in de evaluatie van AI-modellen naar voren als

Beste open source gezondheidszorgdatasets voor machine learning-projecten
Het mondiale gezondheidszorgsysteem produceert dagelijks enorme hoeveelheden medische gegevens, die het potentieel hebben om te worden gebruikt voor machine learning-toepassingen.

Navigeren door gegevensprivacy in AI: strategieën voor compliance en innovatie
Inleiding In het snel evoluerende landschap van kunstmatige intelligentie (AI) worden bedrijven als OpenAI geconfronteerd met aanzienlijke uitdagingen bij het balanceren van de onverzadigbare behoefte aan data met strenge

De toekomst van data met intelligente karakterherkenning (ICR)
Handgeschreven notities hebben zelfs in onze digitale wereld een bijzondere charme. Intelligent Character Recognition (ICR) helpt de analoge en digitale kloof te overbruggen door handgeschreven tekst te converteren

De impact van NLP op gezondheidszorgdiagnostiek
Natural Language Processing (NLP) transformeert de manier waarop we omgaan met technologie. Het verwerkt menselijke taal om een enorm informatiepotentieel te ontsluiten. De technologie heeft hetzelfde potentieel

De juiste spraakherkenningsdataset kiezen voor uw AI-model
Stel je voor dat je interactie hebt met Siri of Alexa. Hun vermogen om onze toespraak te begrijpen is fascinerend. Deze mogelijkheid komt voort uit de datasets die in hun training worden gebruikt. Deze

Datasets voor de gezondheidszorg: zegen voor AI in de gezondheidszorg
Kunstmatige intelligentie, een term die ooit vooral in science fiction werd gebruikt, is nu een realiteit die de groei van verschillende industrieën stimuleert. Next Move Strategieadvies

Versterkend leren met menselijke feedback: definitie en stappen
Reinforcement Learning (RL) is een vorm van machinaal leren. Bij deze aanpak leren algoritmen beslissingen te nemen met vallen en opstaan, net zoals mensen dat doen.

Oorzaken van AI-hallucinaties (en technieken om deze te verminderen)
AI-hallucinaties verwijzen naar gevallen waarin AI-modellen, met name grote taalmodellen (LLM's), informatie genereren die waar lijkt, maar onjuist is of geen verband houdt met de werkelijkheid.

Wat is klinische validatie? Uw gids voor best practices en processen
Bedenk een scenario waarin een nieuw diagnostisch hulpmiddel wordt ontwikkeld. Artsen zijn enthousiast over de mogelijkheden ervan. Maar voordat ze het in de routinematige zorg integreerden,

Het belang van ethische AI/eerlijke AI en soorten vooroordelen die moeten worden vermeden
In het snelgroeiende veld van kunstmatige intelligentie (AI) is de focus op ethische overwegingen en eerlijkheid meer dan een morele imperatief: het is een fundamentele noodzaak voor

Samenvatting van AI-medische dossiers: definitie, uitdagingen en best practices
De groei van medische dossiers in de gezondheidszorg is zowel een uitdaging als een kans geworden. Stel je een wereld voor waarin elk detail in een

Klinische gegevensabstractie: definitie, proces en meer
Ziekenhuizen en klinieken krijgen jaarlijks duizenden patiënten te verwerken. Dit vereist een groot aantal toegewijde artsen en verpleegkundigen. Zij werken onvermoeibaar om zorg te verlenen

Synthetische gegevens in de gezondheidszorg: definitie, voordelen en uitdagingen
Stel je een scenario voor waarin onderzoekers een nieuw medicijn ontwikkelen. Ze hebben uitgebreide patiëntgegevens nodig om te kunnen testen, maar er zijn grote zorgen over privacy en privacy

HIPAA-expertbepaling voor de-identificatie
De Health Insurance Portability and Accountability Act (HIPAA) zet de norm voor de bescherming van patiëntgegevens in de gezondheidszorg. Een cruciaal aspect hiervan is het de-identificeren van Protected

Baanbrekend oncologisch onderzoek met NLP: de doorbraak van Shaip
Casestudy downloaden In de zoektocht om kanker te overwinnen zijn gegevens net zo belangrijk als vastberadenheid. Bij Shaip zijn we er trots op dat we een grote sprong voorwaarts hebben kunnen maken

De kracht van natuurlijke taalverwerking (NLP) in de radiologie: verbetering van de diagnose en efficiëntie
Radiologie speelt een cruciale rol in de gezondheidszorg. Het maakt gebruik van beeldvormingstechnieken zoals CT-scans, röntgenfoto's en MRI om verschillende aandoeningen te diagnosticeren en te behandelen. Natuurlijke taal

De rol van natuurlijke taalverwerking (NLP) in de oncologie
Kanker vormt wereldwijd een aanzienlijk gezondheidsprobleem. Het gebeurt wanneer cellen op een ongecontroleerde manier groeien en zich verspreiden. Het is de tweede belangrijkste doodsoorzaak

Alles wat u moet weten over versterkend leren van menselijke feedback
In 2023 was er sprake van een enorme toename in de adoptie van AI-tools zoals ChatGPT. Deze golf veroorzaakte een levendig debat en mensen bespreken de voordelen van AI,

De kracht van AI in de auto-industrie
Als het gaat om de integratie van AI in auto’s, staat de wereld op een opmerkelijk kruispunt. Stel je voor dat je op een drukke weg rijdt met AI en je gegevens beheert

Voordelen van tekst-naar-spraak in alle sectoren
Tekst-naar-spraak (TTS)-technologie is een innovatieve oplossing die geschreven tekst omzet in gesproken woorden. Het is een game-changer geworden in verschillende industrieën en heeft een revolutie teweeggebracht

De A tot Z van gegevensannotatie
Een beginnershandleiding voor gegevensannotatie: tips en praktische tips De ultieme kopersgids 2024 Indextabel Inleiding Wat is machinaal leren? Wat is

Gids voor de-identificatie van gegevens: alles wat een beginner moet weten (in 2024)
In het tijdperk van digitale transformatie verschuiven zorgorganisaties hun activiteiten snel naar digitale platforms. Dit brengt weliswaar efficiëntie en gestroomlijnde processen met zich mee, maar ook

Generatieve AI in de gezondheidszorg: toepassingen, voordelen, uitdagingen en toekomstige trends
De gezondheidszorg is altijd een gebied geweest waar innovatie wordt gewaardeerd en cruciaal is voor het redden van levens. Ondanks de technologische vooruitgang wordt de gezondheidszorgsector nog steeds geconfronteerd met aanhoudende uitdagingen.

Verschil tussen verantwoorde AI en ethische AI
De snelgroeiende mondiale AI-markt zal naar verwachting in 1847 een omvang van 2030 miljard dollar bereiken. Nu AI centraal staat in ons leven, weten we wat voor soort
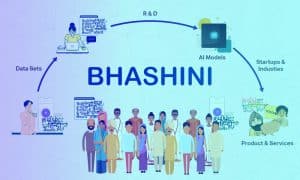
Hoe Bhasini de taalinclusiviteit van India stimuleert
Premier Narendra Modi onthulde “Bhashini” tijdens de G20-werkgroep ministers voor de digitale economie. Dit door AI aangedreven taalvertaalplatform viert de taalkundige diversiteit van India. Bhashini



















Medische beeldannotatie: definitie, toepassing, gebruiksscenario's en typen
Medische beeldannotatie speelt een cruciale rol bij het voorzien van machine learning-algoritmen en AI-modellen van de nodige trainingsgegevens. Dit proces is essentieel voor
Ethiek en vooringenomenheid: navigeren door de uitdagingen van de samenwerking tussen mens en AI bij modelevaluatie
In de zoektocht om de transformerende kracht van kunstmatige intelligentie (AI) te benutten, staat de technologiegemeenschap voor een cruciale uitdaging: het waarborgen van ethische integriteit en het minimaliseren van vooroordelen
The Human Touch: AI-creativiteit verbeteren met subjectieve evaluatie
In de snel evoluerende wereld van kunstmatige intelligentie (AI) is de zoektocht naar creativiteit niet langer alleen een menselijke onderneming. De huidige AI-technologieën zijn aan het breken
Zoekrelevantie maximaliseren met gegevenslabeling: tips en best practices
Gebruikers worden tegenwoordig ondergedompeld in enorme hoeveelheden informatie, wat het vinden van de informatie die ze nodig hebben complex maakt. Zoekrelevantie meet de nauwkeurigheid van informatie
De kloof overbruggen: menselijke intuïtie integreren in de evaluatie van AI-modellen
Inleiding In een tijdperk waarin kunstmatige intelligentie (AI) elk facet van ons leven vormgeeft, komt de integratie van menselijke intuïtie in de evaluatie van AI-modellen naar voren als
Beste open source gezondheidszorgdatasets voor machine learning-projecten
Het mondiale gezondheidszorgsysteem produceert dagelijks enorme hoeveelheden medische gegevens, die het potentieel hebben om te worden gebruikt voor machine learning-toepassingen.
Navigeren door gegevensprivacy in AI: strategieën voor compliance en innovatie
Inleiding In het snel evoluerende landschap van kunstmatige intelligentie (AI) worden bedrijven als OpenAI geconfronteerd met aanzienlijke uitdagingen bij het balanceren van de onverzadigbare behoefte aan data met strenge
De toekomst van data met intelligente karakterherkenning (ICR)
Handgeschreven notities hebben zelfs in onze digitale wereld een bijzondere charme. Intelligent Character Recognition (ICR) helpt de analoge en digitale kloof te overbruggen door handgeschreven tekst te converteren
De impact van NLP op gezondheidszorgdiagnostiek
Natural Language Processing (NLP) transformeert de manier waarop we omgaan met technologie. Het verwerkt menselijke taal om een enorm informatiepotentieel te ontsluiten. De technologie heeft hetzelfde potentieel
De juiste spraakherkenningsdataset kiezen voor uw AI-model
Stel je voor dat je interactie hebt met Siri of Alexa. Hun vermogen om onze toespraak te begrijpen is fascinerend. Deze mogelijkheid komt voort uit de datasets die in hun training worden gebruikt. Deze
Datasets voor de gezondheidszorg: zegen voor AI in de gezondheidszorg
Kunstmatige intelligentie, een term die ooit vooral in science fiction werd gebruikt, is nu een realiteit die de groei van verschillende industrieën stimuleert. Next Move Strategieadvies
Versterkend leren met menselijke feedback: definitie en stappen
Reinforcement Learning (RL) is een vorm van machinaal leren. Bij deze aanpak leren algoritmen beslissingen te nemen met vallen en opstaan, net zoals mensen dat doen.
Oorzaken van AI-hallucinaties (en technieken om deze te verminderen)
AI-hallucinaties verwijzen naar gevallen waarin AI-modellen, met name grote taalmodellen (LLM's), informatie genereren die waar lijkt, maar onjuist is of geen verband houdt met de werkelijkheid.
Wat is klinische validatie? Uw gids voor best practices en processen
Bedenk een scenario waarin een nieuw diagnostisch hulpmiddel wordt ontwikkeld. Artsen zijn enthousiast over de mogelijkheden ervan. Maar voordat ze het in de routinematige zorg integreerden,
Het belang van ethische AI/eerlijke AI en soorten vooroordelen die moeten worden vermeden
In het snelgroeiende veld van kunstmatige intelligentie (AI) is de focus op ethische overwegingen en eerlijkheid meer dan een morele imperatief: het is een fundamentele noodzaak voor
Samenvatting van AI-medische dossiers: definitie, uitdagingen en best practices
De groei van medische dossiers in de gezondheidszorg is zowel een uitdaging als een kans geworden. Stel je een wereld voor waarin elk detail in een
Klinische gegevensabstractie: definitie, proces en meer
Ziekenhuizen en klinieken krijgen jaarlijks duizenden patiënten te verwerken. Dit vereist een groot aantal toegewijde artsen en verpleegkundigen. Zij werken onvermoeibaar om zorg te verlenen
Synthetische gegevens in de gezondheidszorg: definitie, voordelen en uitdagingen
Stel je een scenario voor waarin onderzoekers een nieuw medicijn ontwikkelen. Ze hebben uitgebreide patiëntgegevens nodig om te kunnen testen, maar er zijn grote zorgen over privacy en privacy
HIPAA-expertbepaling voor de-identificatie
De Health Insurance Portability and Accountability Act (HIPAA) zet de norm voor de bescherming van patiëntgegevens in de gezondheidszorg. Een cruciaal aspect hiervan is het de-identificeren van Protected
Baanbrekend oncologisch onderzoek met NLP: de doorbraak van Shaip
Casestudy downloaden In de zoektocht om kanker te overwinnen zijn gegevens net zo belangrijk als vastberadenheid. Bij Shaip zijn we er trots op dat we een grote sprong voorwaarts hebben kunnen maken
De kracht van natuurlijke taalverwerking (NLP) in de radiologie: verbetering van de diagnose en efficiëntie
Radiologie speelt een cruciale rol in de gezondheidszorg. Het maakt gebruik van beeldvormingstechnieken zoals CT-scans, röntgenfoto's en MRI om verschillende aandoeningen te diagnosticeren en te behandelen. Natuurlijke taal
De rol van natuurlijke taalverwerking (NLP) in de oncologie
Kanker vormt wereldwijd een aanzienlijk gezondheidsprobleem. Het gebeurt wanneer cellen op een ongecontroleerde manier groeien en zich verspreiden. Het is de tweede belangrijkste doodsoorzaak
Alles wat u moet weten over versterkend leren van menselijke feedback
In 2023 was er sprake van een enorme toename in de adoptie van AI-tools zoals ChatGPT. Deze golf veroorzaakte een levendig debat en mensen bespreken de voordelen van AI,
De kracht van AI in de auto-industrie
Als het gaat om de integratie van AI in auto’s, staat de wereld op een opmerkelijk kruispunt. Stel je voor dat je op een drukke weg rijdt met AI en je gegevens beheert
Voordelen van tekst-naar-spraak in alle sectoren
Tekst-naar-spraak (TTS)-technologie is een innovatieve oplossing die geschreven tekst omzet in gesproken woorden. Het is een game-changer geworden in verschillende industrieën en heeft een revolutie teweeggebracht
De A tot Z van gegevensannotatie
Een beginnershandleiding voor gegevensannotatie: tips en praktische tips De ultieme kopersgids 2024 Indextabel Inleiding Wat is machinaal leren? Wat is
Gids voor de-identificatie van gegevens: alles wat een beginner moet weten (in 2024)
In het tijdperk van digitale transformatie verschuiven zorgorganisaties hun activiteiten snel naar digitale platforms. Dit brengt weliswaar efficiëntie en gestroomlijnde processen met zich mee, maar ook
Generatieve AI in de gezondheidszorg: toepassingen, voordelen, uitdagingen en toekomstige trends
De gezondheidszorg is altijd een gebied geweest waar innovatie wordt gewaardeerd en cruciaal is voor het redden van levens. Ondanks de technologische vooruitgang wordt de gezondheidszorgsector nog steeds geconfronteerd met aanhoudende uitdagingen.
Verschil tussen verantwoorde AI en ethische AI
De snelgroeiende mondiale AI-markt zal naar verwachting in 1847 een omvang van 2030 miljard dollar bereiken. Nu AI centraal staat in ons leven, weten we wat voor soort
Hoe Bhasini de taalinclusiviteit van India stimuleert
Premier Narendra Modi onthulde “Bhashini” tijdens de G20-werkgroep ministers voor de digitale economie. Dit door AI aangedreven taalvertaalplatform viert de taalkundige diversiteit van India. Bhashini

Wat is NLP? Hoe het werkt, voordelen, uitdagingen, voorbeelden
Download infographics Wat is NLP? Natural Language Processing (NLP) is een onderdeel van kunstmatige intelligentie (AI). Het stelt robots in staat om menselijke taal te analyseren en te begrijpen,

OCR - Definitie, voordelen, uitdagingen en gebruiksscenario's [Infographic]
OCR is een technologie waarmee machines gedrukte tekst en afbeeldingen kunnen lezen. Het wordt vaak gebruikt in zakelijke toepassingen, zoals het digitaliseren van documenten voor opslag of verwerking, en in consumententoepassingen, zoals het scannen van een ontvangstbewijs voor onkostenvergoeding.

De staat van gespreks-AI 2022
The State ofConversational AI 2022 Wat isConversational AI? Een programmatische en intelligente manier om een gesprekservaring aan te bieden door gesprekken met echte mensen na te bootsen, via digitale en telecommunicatie

Wat is gegevensverzameling? Alles wat een beginner moet weten
Intelligente #AI/ #ML-modellen zijn overal, of het nu gaat om voorspellende zorgmodellen, proactieve diagnose,

Wat is datalabeling? Alles wat een beginner moet weten
Download infographics Intelligente AI-modellen moeten uitgebreid worden getraind om patronen en objecten te kunnen identificeren en uiteindelijk betrouwbare beslissingen te kunnen nemen. Echter, de getrainde