



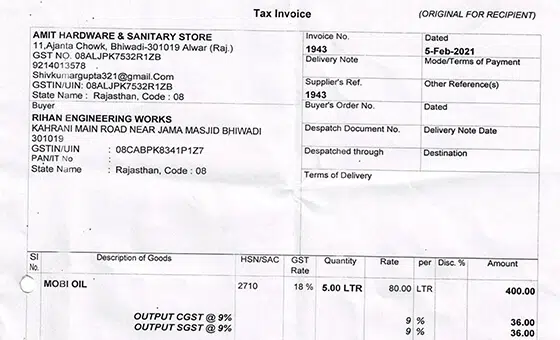

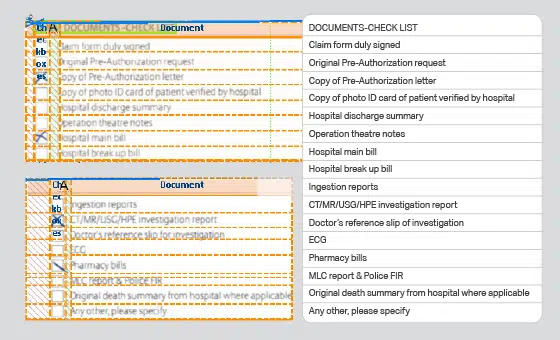


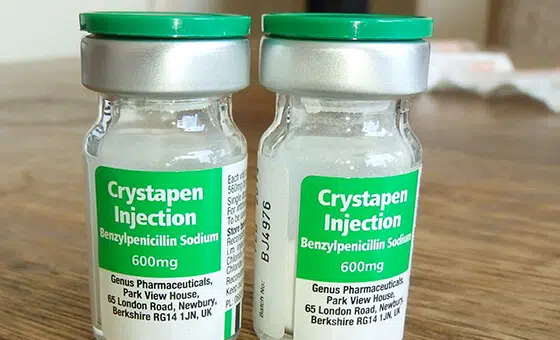



- Use case: Objectherkenningsmodel
- Formaat: Video's
- Volume: 5,000+
- annotatie: Nee

- Use case: Doc. Erkenningsmodel
- Formaat: Afbeeldingen
- Volume: 15,900+
- annotatie: Nee
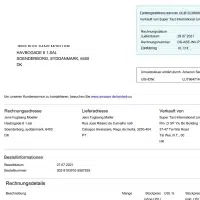
- Use case: Factuur herkennen. Model
- Formaat: Afbeeldingen
- Volume: 45,000+
- annotatie: Nee

- Use case: Nr. Plaatherkenning
- Formaat: Afbeeldingen
- Volume: 3,500+
- annotatie: Nee

- Use case: OCR-model
- Formaat: Afbeeldingen
- Volume: 90,000+
- annotatie: Ja

- Use case: Meertalig OCR-model
- Formaat: Afbeeldingen
- Volume: 23,500+
- annotatie: Ja
- Use case: Objectdetectiemodel
- Formaat: Afbeeldingen
- Volume: 11,500+
- annotatie: Nee

- Use case: Ontvangst AI-modellen
- Formaat: Afbeeldingen
- Volume: 75,000+
- annotatie: Nee

Mensen
Toegewijde en getrainde teams:
- 30,000+ medewerkers voor gegevensverzameling, etikettering en kwaliteitscontrole
- Gecertificeerd projectmanagementteam
- Ervaren productontwikkelingsteam
- Talentpool Sourcing & Onboarding-team

Proces
De hoogste procesefficiëntie wordt gegarandeerd met:
- Robuust 6 Sigma Stage-Gate-proces
- Een toegewijd team van 6 Sigma black belts – Key process owners & Quality compliance
- Continue verbetering en feedbacklus

Platform
Het gepatenteerde platform biedt voordelen:
- Webgebaseerd end-to-end platform
- Onberispelijke kwaliteit
- Snellere TAT
- Naadloze levering



Het creëren van klinische NLP is een cruciale taak die enorme domeinexpertise vereist om op te lossen. Ik kan duidelijk zien dat u Google op dit gebied een aantal jaren voor loopt. Ik wil met je samenwerken en je opschalen.
Google, Inc. Director
Mijn technische team werkte meer dan 2 jaar samen met Shaip's team tijdens de ontwikkeling van spraak-API's voor de gezondheidszorg. We zijn onder de indruk van hun werk in zorgspecifieke NLP en wat ze kunnen bereiken met complexe datasets.
Google, Inc. Hoofd van Engineering