
De sleutel tot het overwinnen van obstakels voor AI-ontwikkeling: betrouwbaardere gegevens
Tegenwoordig heeft de gemiddelde persoon nu miljoenen keren meer rekenkracht op zak dan NASA moest maken voor de maanlanding in 1969. Datzelfde alomtegenwoordige apparaat dat handig een overvloed aan rekenkracht laat zien, voldoet ook aan een andere voorwaarde voor de gouden eeuw van AI: een overvloed aan gegevens. Volgens inzichten van de Information Overload Research Group is 90% van de gegevens in de wereld in de afgelopen twee jaar gecreëerd. Nu de exponentiële groei in rekenkracht eindelijk is samengekomen met een even snelle groei in het genereren van gegevens, exploderen AI-gegevensinnovaties zo sterk dat sommige experts denken dat ze een vliegende start zullen maken voor een vierde industriële revolutie.
Gegevens van de National Venture Capital Association geven aan dat de AI-sector in het eerste kwartaal van 6.9 een recordbedrag van $ 2020 miljard aan investeringen zag. Het is niet moeilijk om het potentieel van AI-tools te zien, omdat het al overal om ons heen wordt aangeboord. Enkele van de meer zichtbare use-cases voor AI-producten zijn de aanbevelingsmotoren achter onze favoriete applicaties zoals Spotify en Netflix. Hoewel het leuk is om een nieuwe artiest te ontdekken om naar te luisteren of een nieuwe tv-show om te bingewatchen, zijn deze implementaties vrij laagdrempelig. Andere algoritmen beoordelen testscores - die deels bepalen waar studenten worden toegelaten tot de universiteit - en weer anderen doorzoeken cv's van kandidaten en beslissen welke sollicitanten een bepaalde baan krijgen. Sommige AI-tools kunnen zelfs gevolgen hebben voor leven of dood, zoals het AI-model dat screent op borstkanker (dat beter presteert dan artsen).
Ondanks de gestage groei in zowel praktijkvoorbeelden van AI-ontwikkeling als het aantal startups dat wedijvert om de volgende generatie transformationele tools te creëren, blijven er uitdagingen voor effectieve ontwikkeling en implementatie. In het bijzonder is AI-output slechts zo nauwkeurig als input toelaat, wat betekent dat kwaliteit voorop staat.

Navigeren door complexe compliance-eisen
Alsof het vinden van kwaliteitsgegevens nog niet moeilijk genoeg was, zijn sommige van de sectoren die het meeste kunnen halen uit AI-gegevensinnovaties ook het zwaarst gereguleerd. Gezondheidszorg is misschien wel het beste voorbeeld, en hoewel uit een onderzoek van HIT Infrastructure bleek dat 91% van de insiders uit de industrie denkt dat de technologie de toegang tot zorg zou kunnen verbeteren, wordt dat optimisme getemperd door het feit dat 75% het ziet als een bedreiging voor de veiligheid en privacy van patiënten - en patiënten zijn niet de enigen die risico lopen.
De ingrijpende voorschriften die zijn uitgevaardigd via de Health Insurance Portability and Accountability Act kruisen nu verschillende lokale obstakels voor gegevenscompliance, zoals de Europese Algemene Verordening Gegevensbescherming, de California Consumer Privacy Act in de Verenigde Staten en de Personal Data Protection Act in Singapore. Naast deze lokale regelgeving zullen er nog veel meer volgen, en aangezien telezorg een belangrijkere bron van gezondheidsgegevens wordt, is het waarschijnlijk dat de regelgeving een nog strakkere greep krijgt op patiëntgegevens die onderweg zijn. Als gevolg hiervan zal het veilige en compliant cloudplatform van Shaip een nog waardevoller middel blijken te zijn om gezondheidsgegevens te verzamelen en te openen om AI-producten te trainen.
Persoonlijk identificeerbare informatie kan een aanzienlijke bedreiging vormen voor uw AI-ontwikkeling, maar zelfs een volledig conforme implementatie loopt gevaar als deze niet het soort nauwkeurige resultaten kan opleveren dat alleen wordt geleverd met diverse trainingsgegevens. Een studie uit 2020 in de Journal of the American Medical Association toonde aan dat algoritmen voor machinaal leren in de medische sector meestal worden getraind met gegevens van patiënten in Californië, New York en Massachusetts. Gezien het feit dat deze patiënten minder dan een vijfde van de Amerikaanse bevolking vertegenwoordigen, om nog maar te zwijgen van de rest van de wereld, is het moeilijk voor te stellen hoe deze modellen iets anders zouden kunnen opleveren dan bevooroordeelde resultaten.

 Shaip erkent de moeilijkheid bij het beveiligen van conforme, geografisch diverse informatie en biedt gelicentieerde gezondheidsgegevens uit een groot aantal verschillende regio's die specifiek zijn samengesteld met als doel nauwkeurige algoritmen te construeren. Deze gegevens komen in de vorm van tekst, zoals medische dossiers of claiminformatie, medische diagnostische beeldvorming zoals CT-scans, audio zoals gesproken notities van artsen of gesprekken tussen artsen en patiënten, en zelfs video van MRI-resultaten. Het is ook volledig geanonimiseerd en geanonimiseerd, waardoor uw organisatie wordt beschermd tegen zowel de ethische als financiële implicaties die kunnen voortvloeien uit een inbreuk op het toenemende aantal voorschriften die gegevens van zowel binnenlandse als internationale oorsprong regelen.
Shaip erkent de moeilijkheid bij het beveiligen van conforme, geografisch diverse informatie en biedt gelicentieerde gezondheidsgegevens uit een groot aantal verschillende regio's die specifiek zijn samengesteld met als doel nauwkeurige algoritmen te construeren. Deze gegevens komen in de vorm van tekst, zoals medische dossiers of claiminformatie, medische diagnostische beeldvorming zoals CT-scans, audio zoals gesproken notities van artsen of gesprekken tussen artsen en patiënten, en zelfs video van MRI-resultaten. Het is ook volledig geanonimiseerd en geanonimiseerd, waardoor uw organisatie wordt beschermd tegen zowel de ethische als financiële implicaties die kunnen voortvloeien uit een inbreuk op het toenemende aantal voorschriften die gegevens van zowel binnenlandse als internationale oorsprong regelen.
Obstakels voor AI-ontwikkeling overwinnen
AI-ontwikkelingsinspanningen omvatten aanzienlijke obstakels, ongeacht in welke branche ze plaatsvinden, en het proces om van een haalbaar idee naar een succesvol product te komen, is moeilijk. Tussen de uitdagingen van het verkrijgen van de juiste gegevens en de noodzaak om deze te anonimiseren om te voldoen aan alle relevante regelgeving, kan het voelen alsof het bouwen en trainen van een algoritme het makkelijkste is.
Om uw organisatie alle voordelen te geven die nodig zijn bij het ontwerpen van een baanbrekende nieuwe AI-ontwikkeling, kunt u overwegen om samen te werken met een bedrijf als Shaip. Chetan Parikh en Vatsal Ghiya hebben Shaip opgericht om bedrijven te helpen bij het ontwikkelen van het soort oplossingen dat de gezondheidszorg in de VS zou kunnen transformeren. Na meer dan 16 jaar in het bedrijfsleven, is ons bedrijf uitgegroeid tot meer dan 600 teamleden en hebben we met honderden klanten om overtuigende ideeën om te zetten in AI-oplossingen.
Met onze mensen, processen en platform die voor uw organisatie werken, kunt u onmiddellijk de volgende vier voordelen ontsluiten en uw project naar een succesvol einde katapulteren:
1. Het vermogen om uw datawetenschappers te bevrijden
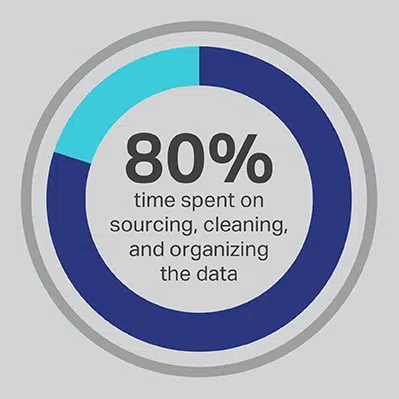
Je kunt er niet omheen dat het AI-ontwikkelingsproces een aanzienlijke tijdsinvestering kost, maar je kunt altijd de functies optimaliseren waaraan je team de meeste tijd besteedt. U hebt uw datawetenschappers ingehuurd omdat ze experts zijn in de ontwikkeling van geavanceerde algoritmen en machine learning-modellen, maar het onderzoek toont consequent aan dat deze werknemers 80% van hun tijd besteden aan het zoeken, opschonen en organiseren van de gegevens die het project mogelijk maken. Meer dan driekwart (76%) van de datawetenschappers meldt dat deze alledaagse processen voor het verzamelen van gegevens ook hun minst favoriete onderdeel van het werk zijn, maar de behoefte aan kwaliteitsgegevens laat slechts 20% van hun tijd over voor daadwerkelijke ontwikkeling. het meest interessante en intellectueel stimulerende werk voor veel datawetenschappers. Door data te sourcen via een externe leverancier zoals Shaip, kan een bedrijf zijn dure en getalenteerde data-engineers hun werk als dataconciërges uitbesteden en in plaats daarvan hun tijd besteden aan de onderdelen van AI-oplossingen waar ze de meeste waarde kunnen produceren.
2. Het vermogen om betere resultaten te behalen
 Veel leiders op het gebied van AI-ontwikkeling besluiten om open-source of crowdsourced-gegevens te gebruiken om de kosten te verlagen, maar deze beslissing kost op de lange termijn bijna altijd meer. Dit soort gegevens is direct beschikbaar, maar ze kunnen niet tippen aan de kwaliteit van zorgvuldig samengestelde datasets. Met name crowdsourced-gegevens zitten vol fouten, weglatingen en onnauwkeurigheden, en hoewel deze problemen soms tijdens het ontwikkelingsproces onder het toeziend oog van uw ingenieurs kunnen worden opgelost, zijn er extra iteraties nodig die niet nodig zouden zijn als u met hogere -kwaliteitsgegevens vanaf het begin.
Veel leiders op het gebied van AI-ontwikkeling besluiten om open-source of crowdsourced-gegevens te gebruiken om de kosten te verlagen, maar deze beslissing kost op de lange termijn bijna altijd meer. Dit soort gegevens is direct beschikbaar, maar ze kunnen niet tippen aan de kwaliteit van zorgvuldig samengestelde datasets. Met name crowdsourced-gegevens zitten vol fouten, weglatingen en onnauwkeurigheden, en hoewel deze problemen soms tijdens het ontwikkelingsproces onder het toeziend oog van uw ingenieurs kunnen worden opgelost, zijn er extra iteraties nodig die niet nodig zouden zijn als u met hogere -kwaliteitsgegevens vanaf het begin.
Vertrouwen op open-sourcegegevens is een andere veelvoorkomende snelkoppeling die zijn eigen reeks valkuilen met zich meebrengt. Een gebrek aan differentiatie is een van de grootste problemen, omdat een algoritme dat is getraind met behulp van open source-gegevens gemakkelijker kan worden gerepliceerd dan een algoritme dat is gebouwd op gelicentieerde datasets. Door deze route te volgen, nodigt u concurrentie uit van andere nieuwkomers in de ruimte die uw prijzen kunnen onderbieden en op elk moment marktaandeel kunnen veroveren. Wanneer u op Shaip vertrouwt, krijgt u toegang tot gegevens van de hoogste kwaliteit die zijn verzameld door bekwaam beheerd personeel, en kunnen we u een exclusieve licentie verlenen voor een aangepaste gegevensset die voorkomt dat concurrenten uw zwaarbevochten intellectuele eigendom gemakkelijk opnieuw kunnen creëren.
3. Toegang tot ervaren professionals
 Zelfs als uw interne rooster bekwame ingenieurs en getalenteerde datawetenschappers omvat, kunnen uw AI-tools profiteren van de wijsheid die alleen door ervaring ontstaat. Onze materiedeskundigen hebben het voortouw genomen bij tal van AI-implementaties in hun vakgebied en hebben onderweg waardevolle lessen geleerd, en hun enige doel is om u te helpen die van u te bereiken.
Zelfs als uw interne rooster bekwame ingenieurs en getalenteerde datawetenschappers omvat, kunnen uw AI-tools profiteren van de wijsheid die alleen door ervaring ontstaat. Onze materiedeskundigen hebben het voortouw genomen bij tal van AI-implementaties in hun vakgebied en hebben onderweg waardevolle lessen geleerd, en hun enige doel is om u te helpen die van u te bereiken.
Met domeinexperts die gegevens voor u identificeren, ordenen, categoriseren en labelen, weet u dat de informatie die wordt gebruikt om uw algoritme te trainen de best mogelijke resultaten kan opleveren. We voeren ook regelmatig kwaliteitsborging uit om ervoor te zorgen dat gegevens voldoen aan de hoogste normen en zullen presteren zoals bedoeld, niet alleen in een laboratorium, maar ook in een praktijksituatie.
4. Een versnelde ontwikkelingstijdlijn
AI-ontwikkeling gebeurt niet van de ene op de andere dag, maar het kan sneller gebeuren als je samenwerkt met Shaip. Interne gegevensverzameling en annotatie creëert een aanzienlijk operationeel knelpunt dat de rest van het ontwikkelingsproces ophoudt. Door met Shaip samen te werken, krijgt u direct toegang tot onze uitgebreide bibliotheek met kant-en-klare gegevens, en onze experts kunnen met onze diepgaande kennis van de branche en ons wereldwijde netwerk elke vorm van aanvullende informatie verkrijgen die u nodig heeft. Zonder de last van sourcing en annotatie, kan uw team meteen aan de slag met de daadwerkelijke ontwikkeling, en ons trainingsmodel kan helpen vroege onnauwkeurigheden te identificeren om de iteraties te verminderen die nodig zijn om de nauwkeurigheidsdoelen te bereiken.
Als u niet klaar bent om alle aspecten van uw gegevensbeheer uit te besteden, biedt Shaip ook een cloudgebaseerd platform waarmee teams verschillende soorten gegevens efficiënter kunnen produceren, wijzigen en annoteren, inclusief ondersteuning voor afbeeldingen, video, tekst en audio . ShaipCloud bevat een verscheidenheid aan intuïtieve validatie- en workflowtools, zoals een gepatenteerde oplossing om workloads te volgen en te bewaken, een transcriptietool om complexe en moeilijke audio-opnames te transcriberen en een kwaliteitscontrolecomponent om compromisloze kwaliteit te garanderen. Het beste van alles is dat het schaalbaar is, zodat het kan groeien naarmate de verschillende eisen van uw project toenemen.
Het tijdperk van AI-innovatie is nog maar net begonnen en we zullen de komende jaren ongelooflijke vooruitgang en innovaties zien die het potentieel hebben om hele industrieën opnieuw vorm te geven of zelfs de samenleving als geheel te veranderen. Bij Shaip willen we onze expertise gebruiken om als transformatieve kracht te dienen en de meest revolutionaire bedrijven ter wereld te helpen de kracht van AI-oplossingen te benutten om ambitieuze doelen te bereiken.
We hebben uitgebreide ervaring met toepassingen in de gezondheidszorg en gespreks-AI, maar we hebben ook de nodige vaardigheden om modellen te trainen voor bijna elk soort toepassing. Voor meer informatie over hoe Shaip u kan helpen uw project van idee tot uitvoering te brengen, kunt u een kijkje nemen bij de vele bronnen die beschikbaar zijn op onze website of neem vandaag nog contact met ons op.
