

Wat zijn grote taalmodellen?
Large Language Models (LLM's) zijn geavanceerde systemen voor kunstmatige intelligentie (AI) die zijn ontworpen om mensachtige tekst te verwerken, te begrijpen en te genereren. Ze zijn gebaseerd op deep learning-technieken en getraind op enorme datasets, meestal met miljarden woorden uit verschillende bronnen, zoals websites, boeken en artikelen. Deze uitgebreide training stelt LLM's in staat om de nuances van taal, grammatica, context en zelfs enkele aspecten van algemene kennis te begrijpen.
Sommige populaire LLM's, zoals OpenAI's GPT-3, maken gebruik van een type neuraal netwerk dat een transformator wordt genoemd, waardoor ze complexe taaltaken met opmerkelijke vaardigheid kunnen uitvoeren. Deze modellen kunnen een breed scala aan taken uitvoeren, zoals:
- Vragen beantwoorden
- Samenvattende tekst
- Talen vertalen
- Inhoud genereren
- Zelfs het aangaan van interactieve gesprekken met gebruikers
Naarmate LLM's blijven evolueren, hebben ze een groot potentieel voor het verbeteren en automatiseren van verschillende toepassingen in verschillende sectoren, van klantenservice en het maken van inhoud tot onderwijs en onderzoek. Ze roepen echter ook ethische en maatschappelijke zorgen op, zoals bevooroordeeld gedrag of misbruik, die moeten worden aangepakt naarmate de technologie voortschrijdt.

Populaire voorbeelden van grote taalmodellen
Hier zijn een paar prominente voorbeelden van LLM's die veel worden gebruikt in verschillende branches:
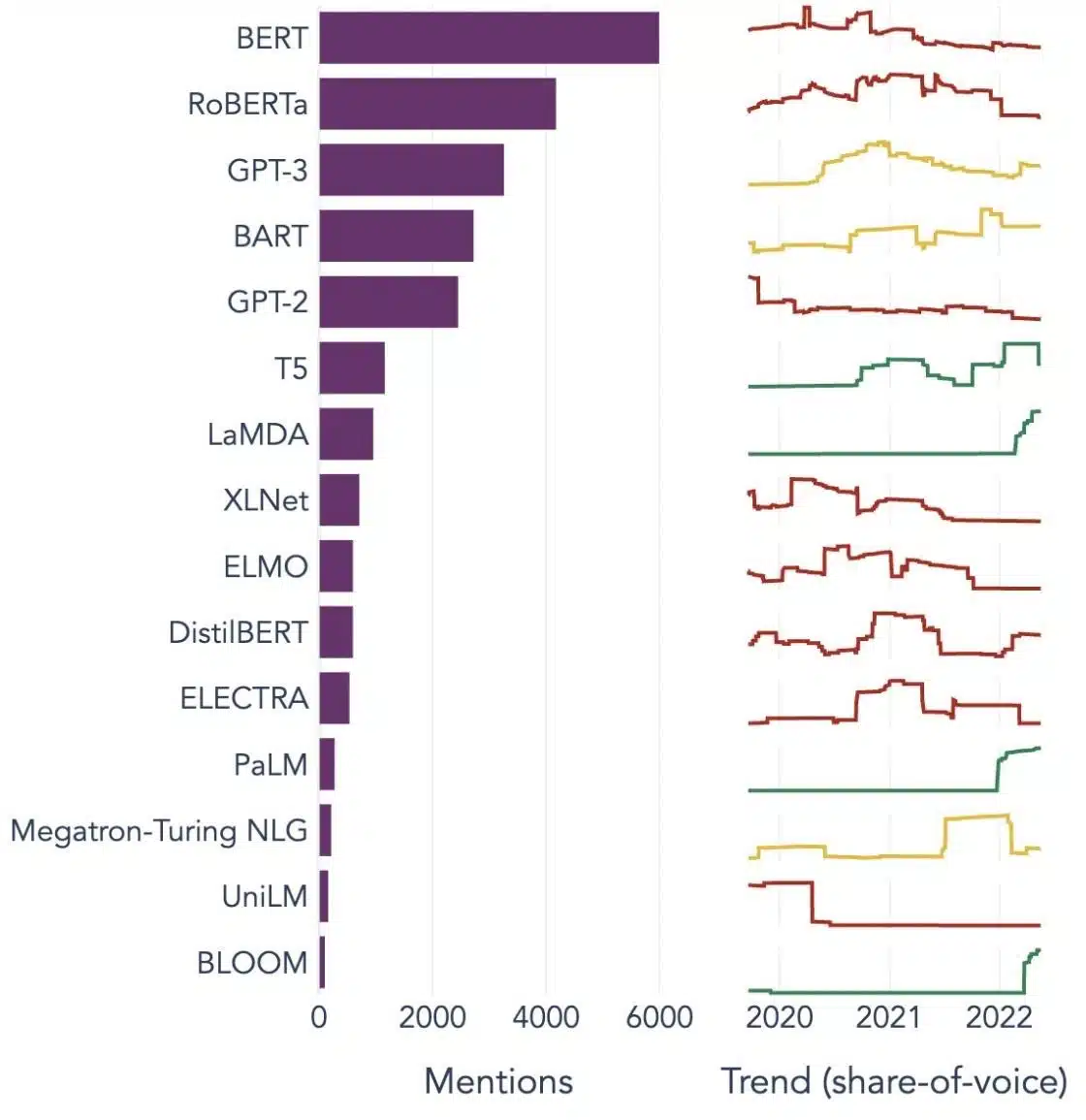
Bron afbeelding: Op weg naar datawetenschap
Hoe worden LLM-modellen getraind?
Het trainen van grote taalmodellen (LLM's) is een hele prestatie die verschillende cruciale stappen met zich meebrengt. Hier is een vereenvoudigd, stapsgewijs overzicht van het proces:
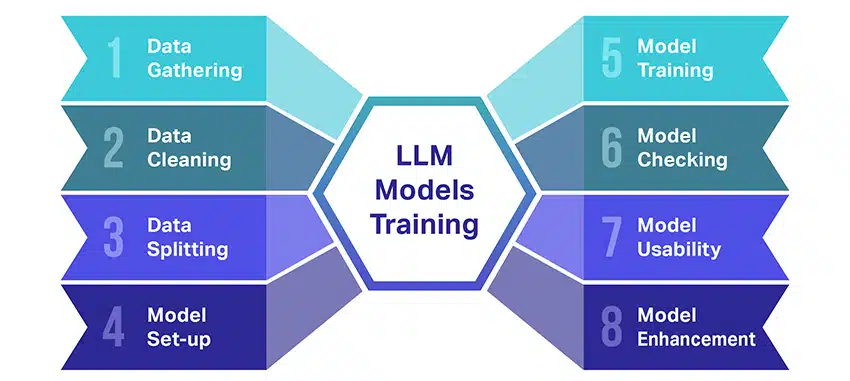
- Tekstgegevens verzamelen: Het trainen van een LLM begint met het verzamelen van een enorme hoeveelheid tekstgegevens. Deze gegevens kunnen afkomstig zijn uit boeken, websites, artikelen of socialemediaplatforms. Het doel is om de rijke diversiteit van de menselijke taal vast te leggen.
- De gegevens opschonen: De onbewerkte tekstgegevens worden vervolgens opgeschoond in een proces dat preprocessing wordt genoemd. Dit omvat taken zoals het verwijderen van ongewenste tekens, het opsplitsen van de tekst in kleinere delen die tokens worden genoemd, en het allemaal in een indeling krijgen waarmee het model kan werken.
- De gegevens splitsen: Vervolgens worden de schone gegevens opgesplitst in twee sets. Eén set, de trainingsgegevens, wordt gebruikt om het model te trainen. De andere set, de validatiegegevens, wordt later gebruikt om de prestaties van het model te testen.
- Het opzetten van het model: Vervolgens wordt de structuur van de LLM, ook wel de architectuur genoemd, gedefinieerd. Dit omvat het selecteren van het type neuraal netwerk en het bepalen van verschillende parameters, zoals het aantal lagen en verborgen eenheden binnen het netwerk.
- Het model trainen: De eigenlijke training begint nu. Het LLM-model leert door naar de trainingsgegevens te kijken, voorspellingen te doen op basis van wat het tot nu toe heeft geleerd en vervolgens de interne parameters aan te passen om het verschil tussen de voorspellingen en de daadwerkelijke gegevens te verkleinen.
- Het model controleren: Het leren van het LLM-model wordt gecontroleerd met behulp van de validatiegegevens. Dit helpt om te zien hoe goed het model presteert en om de instellingen van het model aan te passen voor betere prestaties.
- Het model gebruiken: Na training en evaluatie is het LLM-model klaar voor gebruik. Het kan nu worden geïntegreerd in applicaties of systemen waar het tekst zal genereren op basis van nieuwe input die het krijgt.
- Het model verbeteren: Tot slot is er altijd ruimte voor verbetering. Het LLM-model kan in de loop van de tijd verder worden verfijnd door bijgewerkte gegevens te gebruiken of instellingen aan te passen op basis van feedback en gebruik in de praktijk.
Onthoud dat dit proces aanzienlijke rekenbronnen vereist, zoals krachtige verwerkingseenheden en grote opslag, evenals gespecialiseerde kennis op het gebied van machine learning. Daarom wordt het meestal gedaan door toegewijde onderzoeksorganisaties of bedrijven met toegang tot de nodige infrastructuur en expertise.
Vertrouwt de LLM op begeleid of niet-gesuperviseerd leren?
Grote taalmodellen worden meestal getraind met behulp van een methode die gesuperviseerd leren wordt genoemd. Eenvoudig gezegd betekent dit dat ze leren van voorbeelden die hen de juiste antwoorden laten zien.
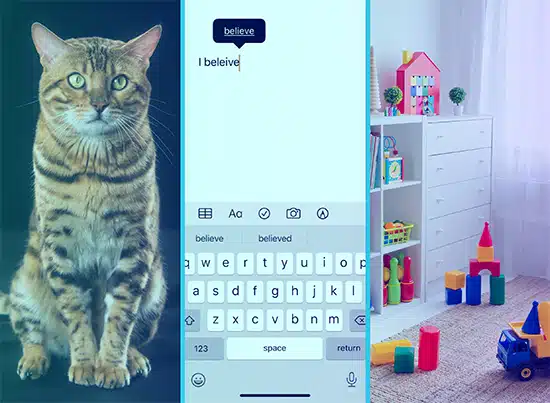 Stel je voor dat je een kind woorden leert door ze plaatjes te laten zien. Je laat ze een foto van een kat zien en zegt 'kat', en ze leren die foto associëren met het woord. Zo werkt begeleid leren. Het model krijgt veel tekst (de "plaatjes") en de corresponderende outputs (de "woorden"), en het leert ze bij elkaar te zoeken.
Stel je voor dat je een kind woorden leert door ze plaatjes te laten zien. Je laat ze een foto van een kat zien en zegt 'kat', en ze leren die foto associëren met het woord. Zo werkt begeleid leren. Het model krijgt veel tekst (de "plaatjes") en de corresponderende outputs (de "woorden"), en het leert ze bij elkaar te zoeken.
Dus als je een LLM een zin geeft, probeert hij het volgende woord of de volgende zin te voorspellen op basis van wat hij van de voorbeelden heeft geleerd. Op deze manier leert het hoe het tekst kan genereren die logisch is en past in de context.
Dat gezegd hebbende, gebruiken LLM's soms ook een beetje leren zonder toezicht. Dit is alsof je het kind een kamer vol met verschillend speelgoed laat verkennen en er zelf over leert. Het model kijkt naar niet-gelabelde gegevens, leerpatronen en structuren zonder de 'juiste' antwoorden te horen.
Gesuperviseerd leren maakt gebruik van gegevens die zijn gelabeld met invoer en uitvoer, in tegenstelling tot leren zonder toezicht, waarbij geen gelabelde uitvoergegevens worden gebruikt.
Kortom, LLM's worden voornamelijk getraind met behulp van gesuperviseerd leren, maar ze kunnen ook ongecontroleerd leren gebruiken om hun capaciteiten te verbeteren, bijvoorbeeld voor verkennende analyse en dimensionaliteitsreductie.
Wat is het datavolume (in GB) dat nodig is om een groot taalmodel te trainen?
De wereld van mogelijkheden voor spraakgegevensherkenning en spraaktoepassingen is immens, en ze worden in verschillende industrieën gebruikt voor een overvloed aan toepassingen.
Het trainen van een groot taalmodel is geen uniform proces, vooral als het gaat om de benodigde gegevens. Het hangt van een heleboel dingen af:
- Het modelontwerp.
- Welk werk moet het doen?
- Het type gegevens dat u gebruikt.
- Hoe goed wil je dat het presteert?
Dat gezegd hebbende, vereist het trainen van LLM's meestal een enorme hoeveelheid tekstgegevens. Maar over hoeveel massa hebben we het? Denk veel verder dan gigabytes (GB). We kijken meestal naar terabytes (TB) of zelfs petabytes (PB) aan gegevens.
Overweeg GPT-3, een van de grootste LLM's die er zijn. Er wordt op getraind 570 GB aan tekstgegevens. Kleinere LLM's hebben misschien minder nodig - misschien 10-20 GB of zelfs 1 GB gigabyte - maar het is nog steeds veel.

Maar het gaat niet alleen om de grootte van de gegevens. Kwaliteit is ook belangrijk. De gegevens moeten schoon en gevarieerd zijn om het model te helpen effectief te leren. En je mag andere belangrijke stukjes van de puzzel niet vergeten, zoals de rekenkracht die je nodig hebt, de algoritmen die je gebruikt voor training en de hardware-instellingen die je hebt. Al deze factoren spelen een grote rol bij het trainen van een LLM.
De opkomst van grote taalmodellen: waarom ze ertoe doen
LLM's zijn niet langer slechts een concept of een experiment. Ze spelen een steeds grotere rol in ons digitale landschap. Maar waarom gebeurt dit? Wat maakt deze LLM's zo belangrijk? Laten we dieper ingaan op enkele belangrijke factoren.
Meesterschap in het nabootsen van menselijke tekst
LLM's hebben de manier veranderd waarop we omgaan met op taal gebaseerde taken. Deze modellen zijn gebouwd met behulp van robuuste machine learning-algoritmen en zijn uitgerust met het vermogen om de nuances van menselijke taal te begrijpen, inclusief context, emotie en zelfs tot op zekere hoogte sarcasme. Dit vermogen om menselijke taal na te bootsen is niet zomaar iets nieuws, het heeft belangrijke implicaties.
De geavanceerde tekstgeneratiemogelijkheden van LLM's kunnen alles verbeteren, van het maken van inhoud tot interacties met de klantenservice.
Stel je voor dat je een digitale assistent een complexe vraag kunt stellen en een antwoord krijgt dat niet alleen logisch is, maar ook samenhangend, relevant en op een gemoedelijke toon wordt afgeleverd. Dat is wat LLM's mogelijk maken. Ze voeden een meer intuïtieve en boeiende interactie tussen mens en machine, verrijken gebruikerservaringen en democratiseren de toegang tot informatie.
Betaalbare rekenkracht
De opkomst van LLM's zou niet mogelijk zijn geweest zonder parallelle ontwikkelingen op het gebied van informatica. Meer specifiek heeft de democratisering van computerbronnen een belangrijke rol gespeeld in de evolutie en acceptatie van LLM's.
Cloudgebaseerde platforms bieden ongekende toegang tot krachtige computerbronnen. Zo kunnen zelfs kleinschalige organisaties en onafhankelijke onderzoekers geavanceerde machine learning-modellen trainen.
Bovendien hebben verbeteringen in verwerkingseenheden (zoals GPU's en TPU's), gecombineerd met de opkomst van gedistribueerd computergebruik, het haalbaar gemaakt om modellen met miljarden parameters te trainen. Deze toegenomen toegankelijkheid van rekenkracht maakt de groei en het succes van LLM's mogelijk, wat leidt tot meer innovatie en toepassingen in het veld.
Verschuivende consumentenvoorkeuren
Consumenten willen tegenwoordig niet alleen antwoorden; ze willen boeiende en herkenbare interacties. Naarmate meer mensen opgroeien met behulp van digitale technologie, is het duidelijk dat de behoefte aan technologie die natuurlijker en menselijker aanvoelt, toeneemt.LLM's bieden een ongeëvenaarde kans om aan deze verwachtingen te voldoen. Door mensachtige tekst te genereren, kunnen deze modellen boeiende en dynamische digitale ervaringen creëren, die de tevredenheid en loyaliteit van gebruikers kunnen vergroten. Of het nu gaat om AI-chatbots die klantenservice bieden of stemassistenten die nieuwsupdates bieden, LLM's luiden een tijdperk in van AI dat ons beter begrijpt.
De ongestructureerde data goudmijn
Ongestructureerde data, zoals e-mails, posts op sociale media en recensies van klanten, is een schat aan inzichten. Naar schatting is dat voorbij 80% van de bedrijfsgegevens is ongestructureerd en groeit met een snelheid van 55% per jaar. Deze gegevens zijn een goudmijn voor bedrijven als ze op de juiste manier worden gebruikt.
LLM's spelen hier een rol, met hun vermogen om dergelijke gegevens op schaal te verwerken en te begrijpen. Ze kunnen taken uitvoeren zoals sentimentanalyse, tekstclassificatie, informatie-extractie en meer, waardoor waardevolle inzichten worden verkregen.
Of het nu gaat om het identificeren van trends uit posts op sociale media of het meten van klantsentiment uit beoordelingen, LLM's helpen bedrijven bij het navigeren door de grote hoeveelheid ongestructureerde gegevens en het nemen van gegevensgestuurde beslissingen.
De groeiende NLP-markt
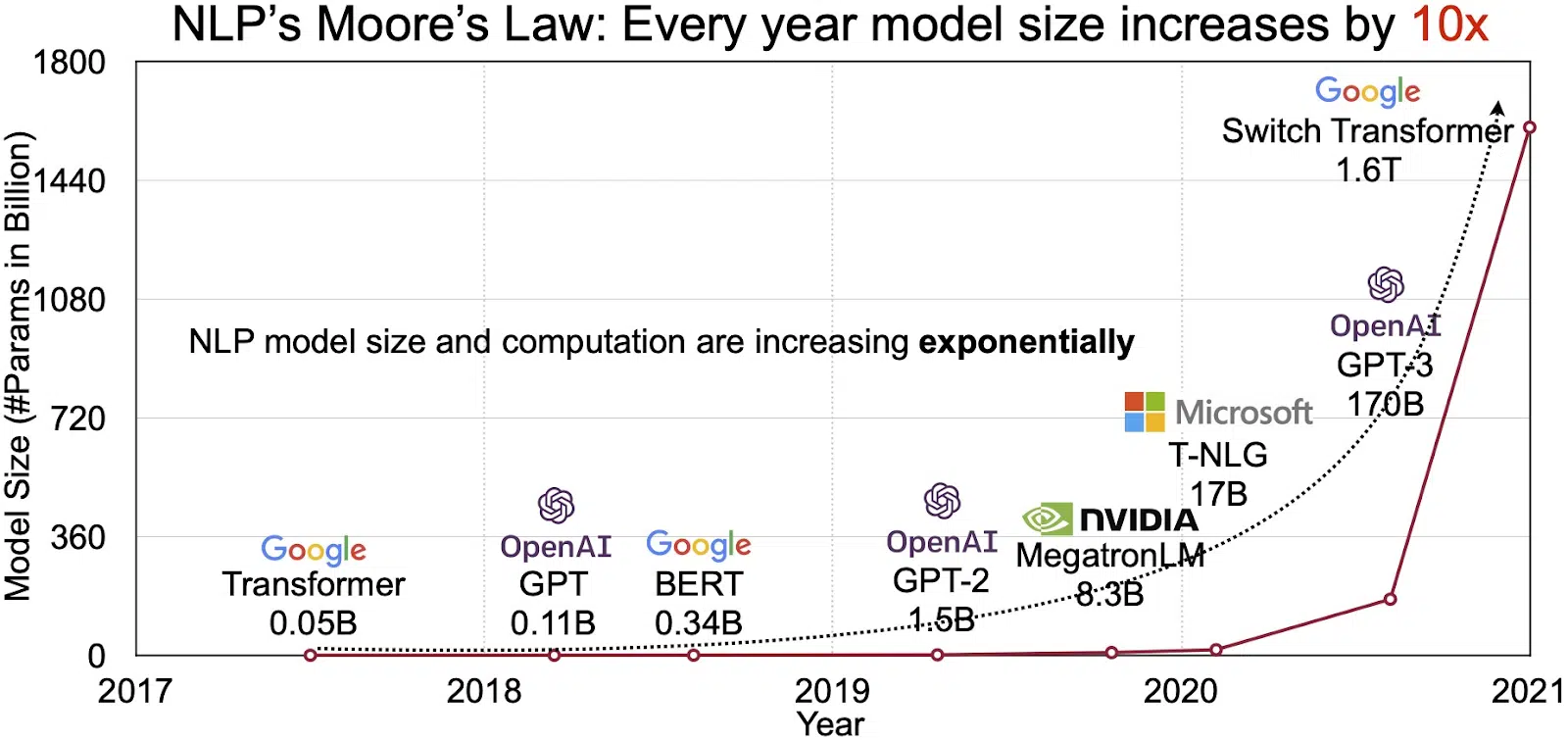
Het potentieel van LLM's wordt weerspiegeld in de snelgroeiende markt voor natuurlijke taalverwerking (NLP). Analisten voorspellen de NLP-markt om uit te breiden $ 11 miljard in 2020 tot meer dan $ 35 miljard in 2026. Maar het is niet alleen de omvang van de markt die groeit. De modellen zelf groeien ook, zowel in fysieke omvang als in het aantal parameters dat ze verwerken. De evolutie van LLM's door de jaren heen, zoals te zien in de onderstaande figuur (bron afbeelding: link), onderstreept hun toenemende complexiteit en capaciteit.
Populaire use cases van grote taalmodellen
Hier zijn enkele van de belangrijkste en meest voorkomende use-cases van LLM:
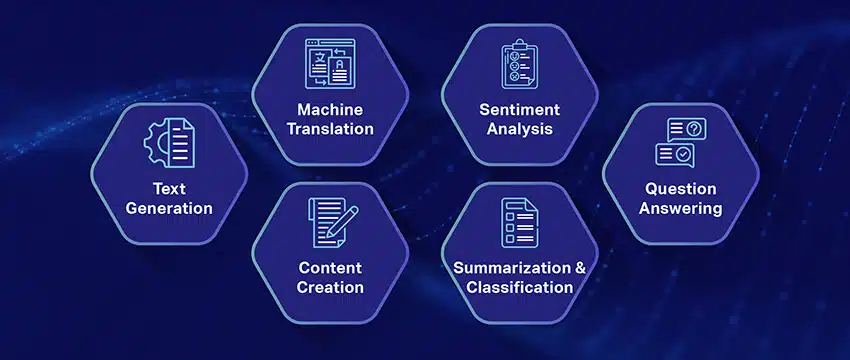
- Tekst in natuurlijke taal genereren: Large Language Models (LLM's) combineren de kracht van kunstmatige intelligentie en computationele taalkunde om autonoom teksten in natuurlijke taal te produceren. Ze kunnen voorzien in diverse gebruikersbehoeften, zoals het schrijven van artikelen, het maken van liedjes of het aangaan van gesprekken met gebruikers.
- Vertaling via machines: LLM's kunnen effectief worden gebruikt om tekst tussen elk talenpaar te vertalen. Deze modellen maken gebruik van deep learning-algoritmen zoals terugkerende neurale netwerken om de taalkundige structuur van zowel de bron- als de doeltaal te begrijpen, waardoor de vertaling van de brontekst naar de gewenste taal wordt vergemakkelijkt.
- Originele inhoud maken: LLM's hebben wegen geopend voor machines om samenhangende en logische inhoud te genereren. Deze inhoud kan worden gebruikt om blogposts, artikelen en andere soorten inhoud te maken. De modellen maken gebruik van hun diepgaande diepgaande leerervaring om de inhoud op een nieuwe en gebruiksvriendelijke manier te formatteren en te structureren.
- Gevoelens analyseren: Een intrigerende toepassing van grote taalmodellen is sentimentanalyse. Hierbij wordt het model getraind om emotionele toestanden en sentimenten in de geannoteerde tekst te herkennen en te categoriseren. De software kan emoties identificeren zoals positiviteit, negativiteit, neutraliteit en andere ingewikkelde sentimenten. Dit kan waardevolle inzichten opleveren in de feedback en meningen van klanten over verschillende producten en diensten.
- Tekst begrijpen, samenvatten en classificeren: LLM's vormen een levensvatbare structuur voor AI-software om de tekst en de context ervan te interpreteren. Door het model te instrueren om enorme hoeveelheden gegevens te begrijpen en te onderzoeken, stellen LLM's AI-modellen in staat om tekst in verschillende vormen en patronen te begrijpen, samen te vatten en zelfs te categoriseren.
- Vragen beantwoorden: Grote taalmodellen rusten Question Answering (QA)-systemen uit met de mogelijkheid om de natuurlijke taalvraag van een gebruiker nauwkeurig waar te nemen en erop te reageren. Populaire voorbeelden van deze use case zijn ChatGPT en BERT, die de context van een zoekopdracht onderzoeken en een uitgebreide verzameling teksten doorzoeken om relevante antwoorden op vragen van gebruikers te leveren.

Part-of-Speech (POS) taggen
Woorden in zinnen worden gelabeld met hun grammaticale functie, zoals werkwoorden, zelfstandige naamwoorden, bijvoeglijke naamwoorden, enz. Dit proces helpt het model bij het begrijpen van de grammatica en de verbanden tussen woorden.

Erkenning van benoemde entiteiten (NER)
Benoemde entiteiten zoals organisaties, locaties en mensen binnen een zin zijn gemarkeerd. Deze oefening helpt het model bij het interpreteren van de semantische betekenissen van woorden en woordgroepen en zorgt voor nauwkeurigere antwoorden.

Sentiment analyse
Aan tekstgegevens worden sentimentlabels toegewezen, zoals positief, neutraal of negatief, waardoor het model de emotionele ondertoon van zinnen kan begrijpen. Het is vooral handig bij het beantwoorden van vragen over emoties en meningen.
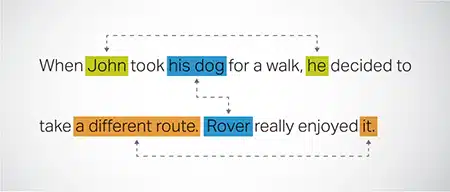
Coreferentie resolutie
Het identificeren en oplossen van gevallen waarin naar dezelfde entiteit wordt verwezen in verschillende delen van een tekst. Deze stap helpt het model de context van de zin te begrijpen, wat leidt tot samenhangende antwoorden.
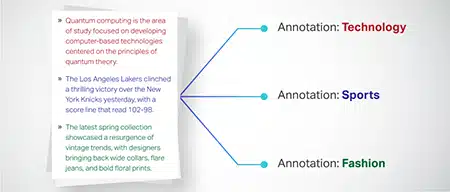
Tekstclassificatie
Tekstgegevens worden gecategoriseerd in vooraf gedefinieerde groepen, zoals productrecensies of nieuwsartikelen. Dit helpt het model bij het onderscheiden van het genre of onderwerp van de tekst, waardoor relevantere antwoorden worden gegenereerd.
Shaips offer
Shaip biedt een breed scala aan diensten om organisaties te helpen bij het beheren, analyseren en optimaal benutten van hun gegevens.
Gegevens webschrapen
Een belangrijke service die Shaip aanbiedt, is het schrapen van gegevens. Dit omvat het extraheren van gegevens uit domeinspecifieke URL's. Door gebruik te maken van geautomatiseerde tools en technieken, kan Shaip snel en efficiënt grote hoeveelheden gegevens van verschillende websites, producthandleidingen, technische documentatie, online forums, online beoordelingen, klantenservicegegevens, brancheregelgevende documenten enz. Schrapen. Dit proces kan van onschatbare waarde zijn voor bedrijven wanneer het verzamelen van relevante en specifieke gegevens uit een groot aantal bronnen.

Machine vertaling
Ontwikkel modellen met behulp van uitgebreide meertalige datasets gecombineerd met bijbehorende transcripties voor het vertalen van tekst in verschillende talen. Dit proces helpt taalkundige belemmeringen weg te nemen en bevordert de toegankelijkheid van informatie.
Taxonomie-extractie en -creatie
Shaip kan helpen bij het extraheren en creëren van taxonomie. Dit omvat het classificeren en categoriseren van gegevens in een gestructureerd formaat dat de relaties tussen verschillende gegevenspunten weerspiegelt. Dit kan met name handig zijn voor bedrijven bij het organiseren van hun gegevens, waardoor deze toegankelijker en gemakkelijker te analyseren zijn. In een e-commercebedrijf kunnen productgegevens bijvoorbeeld worden gecategoriseerd op basis van producttype, merk, prijs, enz., waardoor het voor klanten gemakkelijker wordt om door de productcatalogus te navigeren.
Data Collection
Onze gegevensverzamelingsservices bieden kritieke real-world of synthetische gegevens die nodig zijn voor het trainen van generatieve AI-algoritmen en het verbeteren van de nauwkeurigheid en effectiviteit van uw modellen. De gegevens zijn onbevooroordeeld, ethisch en verantwoord verkregen, rekening houdend met de privacy en beveiliging van gegevens.

Vraag & Antwoord
Vraagbeantwoording (QA) is een deelgebied van natuurlijke taalverwerking gericht op het automatisch beantwoorden van vragen in menselijke taal. QA-systemen zijn getraind op uitgebreide tekst en code, waardoor ze verschillende soorten vragen kunnen behandelen, waaronder feitelijke, definitieve en op meningen gebaseerde vragen. Domeinkennis is cruciaal voor het ontwikkelen van QA-modellen die zijn toegesneden op specifieke gebieden zoals klantenondersteuning, gezondheidszorg of toeleveringsketen. Generatieve QA-benaderingen stellen modellen echter in staat om tekst te genereren zonder domeinkennis, uitsluitend op basis van context.
Ons team van specialisten kan uitgebreide documenten of handleidingen nauwgezet bestuderen om vraag-antwoordparen te genereren, wat de creatie van generatieve AI voor bedrijven vergemakkelijkt. Deze aanpak kan vragen van gebruikers effectief aanpakken door relevante informatie uit een uitgebreid corpus te halen. Onze gecertificeerde experts zorgen voor de productie van Q&A-paren van topkwaliteit die zich uitstrekken over diverse onderwerpen en domeinen.

Tekstsamenvatting
Onze specialisten zijn in staat uitgebreide gesprekken of lange dialogen te destilleren en beknopte en inzichtelijke samenvattingen te leveren uit uitgebreide tekstgegevens.

Tekst genereren
Train modellen met behulp van een brede dataset van tekst in verschillende stijlen, zoals nieuwsartikelen, fictie en poëzie. Deze modellen kunnen vervolgens verschillende soorten inhoud genereren, waaronder nieuwsberichten, blogberichten of posts op sociale media, en bieden een kosteneffectieve en tijdbesparende oplossing voor het maken van inhoud.
Spraakherkenning
Ontwikkel modellen die gesproken taal kunnen begrijpen voor verschillende toepassingen. Dit omvat spraakgestuurde assistenten, dicteersoftware en real-time vertaaltools. Het proces omvat het gebruik van een uitgebreide dataset bestaande uit audio-opnamen van gesproken taal, gecombineerd met de bijbehorende transcripties.

Product aanbevelingen
Ontwikkel modellen met behulp van uitgebreide datasets van koopgeschiedenissen van klanten, inclusief labels die aangeven welke producten klanten geneigd zijn te kopen. Het doel is om klanten nauwkeurige suggesties te geven, waardoor de verkoop wordt gestimuleerd en de klanttevredenheid wordt vergroot.
Ondertiteling van afbeeldingen
Breng een revolutie teweeg in uw beeldinterpretatieproces met onze ultramoderne, AI-gestuurde Image Captioning-service. We brengen vitaliteit in foto's door nauwkeurige en contextueel betekenisvolle beschrijvingen te produceren. Dit maakt de weg vrij voor innovatieve betrokkenheid en interactiemogelijkheden met uw visuele inhoud voor uw publiek.

Training Tekst-naar-spraakdiensten
We bieden een uitgebreide dataset bestaande uit audio-opnamen van menselijke spraak, ideaal voor het trainen van AI-modellen. Deze modellen zijn in staat om natuurlijke en boeiende stemmen voor uw toepassingen te genereren, waardoor uw gebruikers een onderscheidende en meeslepende geluidservaring krijgen.



