
Kunstmatige intelligentie en big data hebben het potentieel om oplossingen te vinden voor mondiale problemen, terwijl prioriteit wordt gegeven aan lokale problemen en de wereld op vele diepgaande manieren wordt getransformeerd. AI biedt oplossingen voor iedereen - en in alle omgevingen, van huizen tot werkplekken. AI-computers, met Machine leren training, kan intelligent gedrag en gesprekken op een geautomatiseerde maar gepersonaliseerde manier simuleren.
Toch heeft AI te maken met een integratieprobleem en is het vaak bevooroordeeld. Gelukkig, focussen op ethiek van kunstmatige intelligentie kan nieuwere mogelijkheden inluiden op het gebied van diversificatie en inclusie door onbewuste vooroordelen te elimineren door middel van diverse trainingsgegevens.
Belang van diversiteit in AI-trainingsdata
 Diversiteit en kwaliteit van trainingsgegevens zijn met elkaar verbonden, aangezien de een de ander beïnvloedt en het resultaat van de AI-oplossing beïnvloedt. Het succes van de AI-oplossing hangt af van de diverse gegevens er wordt op getraind. Datadiversiteit voorkomt dat de AI overfitting uitvoert, wat betekent dat het model alleen presteert of leert van de data die worden gebruikt om te trainen. Bij overfitting kan het AI-model geen resultaten opleveren wanneer het wordt getest op gegevens die niet in de training worden gebruikt.
Diversiteit en kwaliteit van trainingsgegevens zijn met elkaar verbonden, aangezien de een de ander beïnvloedt en het resultaat van de AI-oplossing beïnvloedt. Het succes van de AI-oplossing hangt af van de diverse gegevens er wordt op getraind. Datadiversiteit voorkomt dat de AI overfitting uitvoert, wat betekent dat het model alleen presteert of leert van de data die worden gebruikt om te trainen. Bij overfitting kan het AI-model geen resultaten opleveren wanneer het wordt getest op gegevens die niet in de training worden gebruikt.
De huidige staat van AI-training gegevens
De ongelijkheid of het gebrek aan diversiteit in gegevens zou leiden tot oneerlijke, onethische en niet-inclusieve AI-oplossingen die de discriminatie zouden kunnen verdiepen. Maar hoe en waarom is diversiteit in data gerelateerd aan AI-oplossingen?
Ongelijke vertegenwoordiging van alle klassen leidt tot verkeerde identificatie van gezichten – een belangrijk voorbeeld hiervan is Google Foto's, dat een zwart stel classificeerde als 'gorilla's'. En Meta vraagt een gebruiker die naar een video van zwarte mannen kijkt of de gebruiker 'door wil gaan met het bekijken van video's van primaten'.
Onnauwkeurige of onjuiste classificatie van etnische of raciale minderheden, met name in chatbots, kan bijvoorbeeld leiden tot vooroordelen in AI-trainingssystemen. Volgens het rapport van 2019 op Onderscheidende systemen - geslacht, ras, macht in AI, meer dan 80% van de leraren AI zijn mannen; vrouwelijke AI-onderzoekers op FB vormen slechts 15% en 10% op Google.
De impact van diverse trainingsgegevens op AI-prestaties
 Het weglaten van specifieke groepen en gemeenschappen van gegevensrepresentatie kan leiden tot scheve algoritmen.
Het weglaten van specifieke groepen en gemeenschappen van gegevensrepresentatie kan leiden tot scheve algoritmen.
Databias wordt vaak per ongeluk in de datasystemen geïntroduceerd – door onderbemonstering van bepaalde rassen of groepen. Wanneer gezichtsherkenningssystemen op verschillende gezichten worden getraind, helpt dit het model om specifieke kenmerken te identificeren, zoals de positie van gezichtsorganen en kleurvariaties.
Een ander resultaat van een onevenwichtige frequentie van labels is dat het systeem een minderheid als een anomalie zou kunnen beschouwen wanneer het onder druk wordt gezet om binnen korte tijd een output te produceren.
Diversiteit bereiken in AI-trainingsgegevens
Aan de andere kant is het genereren van een diverse dataset ook een uitdaging. Het pure gebrek aan gegevens over bepaalde klassen kan leiden tot ondervertegenwoordiging. Het kan worden verzacht door de AI-ontwikkelaarsteams diverser te maken met betrekking tot vaardigheden, etniciteit, ras, geslacht, discipline en meer. Bovendien is de ideale manier om datadiversiteitsproblemen in AI aan te pakken, het vanaf het begin aan te pakken in plaats van te proberen te repareren wat er is gedaan - door diversiteit toe te voegen in de fase van gegevensverzameling en -beheer.
Ongeacht de hype rond AI, het hangt nog steeds af van de gegevens die door mensen worden verzameld, geselecteerd en getraind. De aangeboren vooringenomenheid van mensen zal worden weerspiegeld in de door hen verzamelde gegevens, en deze onbewuste vooringenomenheid sluipt ook in de ML-modellen.
Stappen voor het verzamelen en beheren van diverse trainingsgegevens
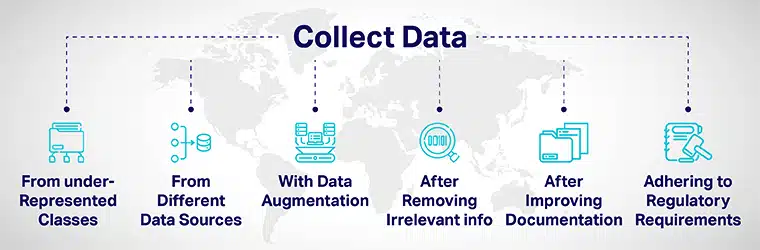
Data diversiteit kan worden bereikt door:
- Voeg zorgvuldig meer gegevens toe van ondervertegenwoordigde klassen en stel uw modellen bloot aan gevarieerde gegevenspunten.
- Door data te verzamelen uit verschillende databronnen.
- Door data-augmentatie of het kunstmatig manipuleren van datasets om nieuwe datapunten toe te voegen/op te nemen die duidelijk verschillen van de oorspronkelijke datapunten.
- Verwijder bij het aannemen van sollicitanten voor het AI-ontwikkelingsproces alle baanrelevante informatie uit de sollicitatie.
- Verbetering van de transparantie en verantwoording door de documentatie van de ontwikkeling en evaluatie van modellen te verbeteren.
- Regelgeving invoeren om diversiteit op te bouwen en inclusiviteit in AI systemen vanaf de basis. Verschillende regeringen hebben richtlijnen ontwikkeld om diversiteit te waarborgen en AI-vooroordelen die oneerlijke resultaten kunnen opleveren, te verminderen.
[Lees ook: Meer informatie over AI-training Gegevensverzamelingsproces ]
Conclusie
Momenteel houden slechts enkele grote technologiebedrijven en leercentra zich exclusief bezig met het ontwikkelen van AI-oplossingen. Deze eliteruimtes zijn doordrenkt van uitsluiting, discriminatie en vooringenomenheid. Dit zijn echter de ruimtes waar AI wordt ontwikkeld, en de logica achter deze geavanceerde AI-systemen zit vol met dezelfde vooroordelen, discriminatie en uitsluiting die worden gedragen door de ondervertegenwoordigde groepen.
Bij het bespreken van diversiteit en non-discriminatie is het belangrijk om vraagtekens te zetten bij de mensen die er baat bij hebben en degenen die er nadeel van ondervinden. We moeten ook kijken naar wie het benadeelt – door het idee van een 'normaal' persoon op te dringen, kan AI mogelijk 'anderen' in gevaar brengen.
Het bespreken van diversiteit in AI-gegevens zonder erkenning van machtsverhoudingen, gelijkheid en rechtvaardigheid zal het grotere plaatje niet laten zien. Om de reikwijdte van diversiteit in AI-trainingsgegevens volledig te begrijpen en hoe mens en AI samen deze crisis kunnen verzachten, neem contact op met de ingenieurs van Shaip. We hebben diverse AI-engineers die dynamische en diverse data kunnen leveren voor uw AI-oplossingen.


