


Wat is Conversationele AI
Conversational AI is een geavanceerde vorm van kunstmatige intelligentie waarmee machines interactieve, mensachtige dialogen met gebruikers kunnen aangaan. Deze technologie begrijpt en interpreteert menselijke taal om natuurlijke gesprekken te simuleren. Het kan in de loop van de tijd leren van interacties om contextueel te reageren.
Conversatie-AI-systemen worden veel gebruikt in toepassingen zoals chatbots, stemassistenten en klantondersteuningsplatforms via digitale en telecommunicatiekanalen.
De markt voor conversationele AI heeft de afgelopen jaren een snelle groei doorgemaakt. Oorspronkelijk ontwikkeld voor amusementsdoeleinden, is conversatie-AI een integraal onderdeel geworden van het digitale ecosysteem. Hier zijn enkele belangrijke statistieken om de impact ervan te illustreren:
- De wereldwijde conversatie-AI-markt werd in 6.8 gewaardeerd op 2021 miljard dollar en zal naar verwachting groeien tot 18.4 miljard dollar in 2026 bij een CAGR van 22.6%. Tegen 2028 zal de marktomvang naar verwachting zijn bereikt $ 29.8 miljard.
- Ondanks de prevalentie, 63% van de gebruikers weet niet dat ze AI in hun dagelijks leven gebruiken.
- A Gartner-enquête ontdekte dat veel bedrijven chatbots als hun primaire AI-toepassing identificeerden, waarbij naar verwachting bijna 70% van de bedienden tegen 2022 dagelijks met conversatieplatforms zal communiceren.
- Sinds de pandemie is het aantal interacties dat wordt afgehandeld door gesprekspartners met maar liefst toegenomen 250% over meerdere industrieën.
- Het aandeel marketeers dat AI gebruikt voor digitale marketing wereldwijd is enorm gestegen, van 29% in 2018 naar 84% in 2020.
- In 2022, 91% van de volwassen gebruikers van stemassistenten gebruikte gespreks-AI-technologie op hun smartphones.
- Bladeren en zoeken naar producten waren de top winkelactiviteiten uitgevoerd met behulp van spraakassistenttechnologie onder Amerikaanse gebruikers in een onderzoek uit 2021.
- Onder techprofessionals wereldwijd bijna 80% gebruik virtuele assistenten voor klantenservice.
- Tegen 2024 gelooft 73% van de Noord-Amerikaanse besluitvormers op het gebied van klantenservice dat online chat, videochat, chatbots of sociale media de meest gebruikte klantenservicekanalen.
- In een onderzoek uit 2021 86% van de Amerikaanse leidinggevenden was het ermee eens dat AI een "mainstream technologie" zou worden binnen hun bedrijf.
- Vanaf februari 2022 53% van de Amerikaanse volwassenen had het afgelopen jaar gecommuniceerd met een AI-chatbot voor klantenservice.
- In 2022, 3.5 miljard wereldwijd werden chatbot-apps gebruikt.
- De top drie redenen Amerikaanse consumenten gebruiken een chatbot voor kantooruren (18%), productinformatie (17%) en verzoeken om klantenservice (16%).
Deze statistieken benadrukken de toenemende acceptatie en invloed van conversationele AI in verschillende sectoren en consumentengedrag.
Hoe werkt gespreks-AI
Conversational AI maakt gebruik van natuurlijke taalverwerking (NLP) en andere geavanceerde algoritmen om contextrijke dialogen aan te gaan. Naarmate de AI een breder scala aan gebruikersinvoer tegenkomt, verbetert het zijn patroonherkenning en voorspellende mogelijkheden. Het proces van conversatie-AI met gebruikers kan worden opgesplitst in vier belangrijke stappen:

Stap 1: Inputverzameling – Gebruikers geven hun input via tekst of spraak.
Stap 2: invoerverwerking – Wanneer de invoer in tekstvorm is, wordt Natural Language Understanding (NLU) gebruikt om betekenis uit de woorden te halen. Voor spraakinvoer wordt eerst automatische spraakherkenning (ASR) gebruikt om audio om te zetten in taaltokens die verder kunnen worden geanalyseerd.
Stap 3: Reactiegeneratie – Technieken voor het genereren van natuurlijke taal worden gebruikt om adequaat te reageren op de vraag van de gebruiker.
Stap 4: Continu verbeteren – Conversational AI-systemen analyseren gebruikersinvoer in de loop van de tijd en verfijnen hun antwoorden om nauwkeurigheid en relevantie te garanderen.



Beperk veelvoorkomende data-uitdagingen in Conversational AI
Conversationele AI transformeert de communicatie tussen mens en computer dynamisch. En veel bedrijven zijn enthousiast over het ontwikkelen van geavanceerde AI-tools en -toepassingen voor gesprekken die de manier waarop zaken worden gedaan kunnen veranderen. Voordat u echter een chatbot ontwikkelt die een betere communicatie tussen u en uw klanten mogelijk maakt, moet u kijken naar de vele ontwikkelingsvalkuilen waarmee u te maken kunt krijgen.
Taalverscheidenheid
 Het is een uitdaging om een chatassistent te ontwikkelen die meerdere talen kan bedienen. Bovendien maakt de enorme diversiteit aan wereldwijde talen het een uitdaging om een chatbot te ontwikkelen die naadloos klantenservice biedt aan alle klanten.
Het is een uitdaging om een chatassistent te ontwikkelen die meerdere talen kan bedienen. Bovendien maakt de enorme diversiteit aan wereldwijde talen het een uitdaging om een chatbot te ontwikkelen die naadloos klantenservice biedt aan alle klanten.
In 2022, ongeveer 1.5 miljard mensen spraken wereldwijd Engels, gevolgd door Chinees Mandarijn met 1.1 miljard sprekers. Hoewel Engels wereldwijd de meest gesproken en bestudeerde vreemde taal is, zijn er slechts ongeveer 20% van de wereldbevolking spreekt het. Het zorgt ervoor dat de rest van de wereldbevolking – 80% – andere talen dan Engels spreekt. Bij het ontwikkelen van een chatbot moet je dus ook rekening houden met taaldiversiteit.
Taalvariabiliteit
Mensen spreken verschillende talen en dezelfde taal anders. Helaas is het voor een machine nog steeds onmogelijk om de variabiliteit van gesproken taal volledig te begrijpen, rekening houdend met de emoties, dialecten, uitspraak, accenten en nuances.
Onze woorden en taalkeuze worden ook weerspiegeld in hoe we typen. Van een machine kan worden verwacht dat hij de variabiliteit van taal alleen begrijpt en waardeert wanneer een groep annotators hem traint op verschillende spraakdatasets.
Dynamiek in spraak
Een andere grote uitdaging bij het ontwikkelen van een conversationele AI is om spraakdynamiek in de strijd te brengen. Zo gebruiken we meerdere fillers, pauzes, zinsdelen en niet te ontcijferen klanken tijdens het praten. Bovendien is spraak veel complexer dan het geschreven woord, omdat we gewoonlijk niet tussen elk woord pauzeren en de nadruk leggen op de juiste lettergreep.
Wanneer we naar anderen luisteren, hebben we de neiging om de bedoeling en betekenis van hun gesprek af te leiden uit onze levenslange ervaringen. Als gevolg hiervan contextualiseren en begrijpen we hun woorden, zelfs als deze dubbelzinnig zijn. Een machine is echter niet in staat tot deze kwaliteit.
Lawaaierige gegevens
Lawaaierige gegevens of achtergrondgeluiden zijn gegevens die geen waarde toevoegen aan de gesprekken, zoals deurbellen, honden, kinderen en andere achtergrondgeluiden. Daarom is het essentieel om de te schrobben of te filteren geluidsbestanden van deze geluiden en train het AI-systeem om de geluiden te identificeren die er toe doen en die dat niet doen.
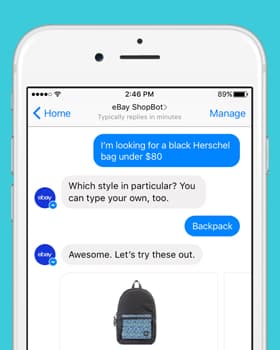
Voor- en nadelen van verschillende soorten spraakgegevens
 Het bouwen van een AI-aangedreven spraakherkenningssysteem of een conversatie-AI vereist tonnen trainings- en testdatasets. Het is echter niet eenvoudig om toegang te krijgen tot dergelijke datasets van hoge kwaliteit – betrouwbaar en voldoend aan uw specifieke projectbehoeften. Toch zijn er opties beschikbaar voor bedrijven die op zoek zijn naar trainingsdatasets, en elke optie heeft voor- en nadelen.
Het bouwen van een AI-aangedreven spraakherkenningssysteem of een conversatie-AI vereist tonnen trainings- en testdatasets. Het is echter niet eenvoudig om toegang te krijgen tot dergelijke datasets van hoge kwaliteit – betrouwbaar en voldoend aan uw specifieke projectbehoeften. Toch zijn er opties beschikbaar voor bedrijven die op zoek zijn naar trainingsdatasets, en elke optie heeft voor- en nadelen.
Als u op zoek bent naar een generiek datasettype, heeft u voldoende openbare spraakopties beschikbaar. Voor iets dat specifieker en relevanter is voor uw projectvereiste, moet u het misschien zelf verzamelen en aanpassen.
Eigen spraakgegevens
De eerste plaats om te zoeken zijn de bedrijfseigen gegevens van uw bedrijf. Aangezien u echter het wettelijke recht en toestemming hebt om uw spraakgegevens van klanten te gebruiken, kunt u deze enorme dataset mogelijk gebruiken voor het trainen en testen van uw projecten.
Voors:
- Geen extra kosten voor het verzamelen van trainingsgegevens
- De trainingsgegevens zijn waarschijnlijk relevant voor uw bedrijf
- Spraakgegevens hebben ook natuurlijke achtergrondakoestiek, dynamische gebruikers en apparaten.
nadelen:
- Het gebruik van dergelijke gegevens kan u een hoop geld kosten aan toestemming om op te nemen en te gebruiken.
- De spraakgegevens kunnen taal-, demografische of klantenbestandbeperkingen hebben
- Gegevens zijn misschien gratis, maar u betaalt nog steeds voor de verwerking, transcriptie, tagging en meer.
Openbare datasets
Openbare spraakdatasets zijn een andere optie als u niet van plan bent de uwe te gebruiken. Deze datasets maken deel uit van het publieke domein en kunnen worden verzameld voor open-sourceprojecten.
VOORDELEN:
- Openbare datasets zijn gratis en ideaal voor projecten met een laag budget
- Ze kunnen onmiddellijk worden gedownload
- Openbare datasets zijn er in verschillende gescripte en niet-gescripte voorbeeldsets.
NADELEN:
- De verwerkings- en kwaliteitsborgingskosten kunnen hoog zijn
- De kwaliteit van openbare spraakdatasets varieert in aanzienlijke mate
- De aangeboden spraakvoorbeelden zijn meestal generiek, waardoor ze ongeschikt zijn voor het ontwikkelen van specifieke spraakprojecten
- De datasets zijn meestal bevooroordeeld ten opzichte van de Engelse taal
Voorverpakte/kant-en-klare datasets
Het verkennen van voorverpakte datasets is een andere optie als openbare gegevens of eigendomsrechten spraakgegevens verzamelen past niet bij uw behoeften.
De verkoper heeft voorverpakte spraakdatasets verzameld met het specifieke doel om door te verkopen aan klanten. Dit type dataset kan worden gebruikt om generieke toepassingen of specifieke doeleinden te ontwikkelen.
VOORDELEN:
- Mogelijk krijgt u toegang tot een dataset die past bij uw specifieke behoefte aan spraakgegevens
- Het is voordeliger om een voorverpakte dataset te gebruiken dan om uw eigen dataset te verzamelen
- Mogelijk krijgt u snel toegang tot de dataset
NADELEN:
- Omdat de dataset voorverpakt is, is deze niet aangepast aan uw projectbehoeften.
- Bovendien is de dataset niet uniek voor uw bedrijf, aangezien elk ander bedrijf het kan kopen.
Kies Op maat verzamelde datasets
Bij het bouwen van een spraaktoepassing heeft u een trainingsdataset nodig die aan al uw specifieke eisen voldoet. Het is echter hoogst onwaarschijnlijk dat u toegang krijgt tot een voorverpakte dataset die voldoet aan de unieke vereisten van uw project. De enige beschikbare optie is om uw dataset te maken of de dataset aan te schaffen via externe leveranciers van oplossingen.
De datasets voor uw trainings- en testbehoeften zijn volledig aanpasbaar. U kunt taaldynamiek, spraakgegevensvariatie en toegang tot verschillende deelnemers opnemen. Bovendien kan de dataset worden geschaald om op tijd aan uw projecteisen te voldoen.
VOORDELEN:
- Datasets worden verzameld voor uw specifieke gebruiksscenario. De kans dat AI-algoritmen afwijken van de beoogde uitkomsten wordt geminimaliseerd.
- Beheers en verminder vooringenomenheid in AI-gegevens
NADELEN:
- De datasets kunnen kostbaar en tijdrovend zijn; de voordelen wegen echter altijd op tegen de kosten.

Industrieën die gebruik maken van gespreks-AI
Momenteel wordt conversatie-AI voornamelijk gebruikt als chatbots. Verschillende industrieën implementeren deze technologie echter om enorme voordelen te behalen. Enkele van de industrieën die gebruik maken van gespreks-AI zijn:
Gezondheidszorg
 Conversational AI heeft een enorme impact op de zorgsector. Conversationele AI heeft bewezen gunstig te zijn voor patiënten, artsen, personeel, verpleegkundigen en ander medisch personeel.
Conversational AI heeft een enorme impact op de zorgsector. Conversationele AI heeft bewezen gunstig te zijn voor patiënten, artsen, personeel, verpleegkundigen en ander medisch personeel.
Enkele van de voordelen zijn:
- Patiëntenbetrokkenheid in de fase na de behandeling
- Chatbots voor het plannen van afspraken
- Veelgestelde vragen en algemene vragen beantwoorden
- Symptoombeoordeling
- Identificeer patiënten in de kritieke zorg
- Escalatie van noodgevallen
E-commerce
 Conversational AI helpt e-commercebedrijven om met hun klanten om te gaan, aangepaste aanbevelingen te doen en producten te verkopen.
Conversational AI helpt e-commercebedrijven om met hun klanten om te gaan, aangepaste aanbevelingen te doen en producten te verkopen.
De e-commerce-industrie maakt tot het uiterste gebruik van de voordelen van deze best-in-class technologie.
- Klantgegevens verzamelen
- Geef relevante productinformatie en aanbevelingen
- Klanttevredenheid verbeteren
- Helpen bij het plaatsen van bestellingen en retouren
- Beantwoord veelgestelde vragen
- Cross- en upsell-producten
Bankieren
 De banksector zet AI-tools voor gesprekken in om klantinteracties te verbeteren, verzoeken in realtime te verwerken en een vereenvoudigde en uniforme klantervaring via meerdere kanalen te bieden.
De banksector zet AI-tools voor gesprekken in om klantinteracties te verbeteren, verzoeken in realtime te verwerken en een vereenvoudigde en uniforme klantervaring via meerdere kanalen te bieden.
- Laat klanten hun saldo in realtime controleren
- Hulp bij stortingen
- Helpen bij het indienen van belastingen en het aanvragen van leningen
- Stroomlijn het bankproces door factuurherinneringen, meldingen en waarschuwingen te verzenden
Verzekering
 Net als de banksector wordt ook de verzekeringssector digitaal aangedreven door conversatie-AI en plukt de vruchten daarvan. Conversatie-AI helpt de verzekeringssector bijvoorbeeld om snellere en betrouwbaardere manieren te bieden om conflicten en claims op te lossen.
Net als de banksector wordt ook de verzekeringssector digitaal aangedreven door conversatie-AI en plukt de vruchten daarvan. Conversatie-AI helpt de verzekeringssector bijvoorbeeld om snellere en betrouwbaardere manieren te bieden om conflicten en claims op te lossen.
- Geef beleidsaanbevelingen
- Snellere schaderegeling
- Elimineer wachttijden
- Verzamel feedback en beoordelingen van klanten
- Creëer bewustzijn bij de klant over beleid
- Beheer sneller claims en verlengingen

Shaip-aanbieding
Als het gaat om het leveren van hoogwaardige en betrouwbare datasets voor het ontwikkelen van geavanceerde spraaktoepassingen voor mens-machine-interactie, is Shaip toonaangevend op de markt met zijn succesvolle implementaties. Met een acuut tekort aan chatbots en spraakassistenten zoeken bedrijven echter steeds vaker de diensten van Shaip – de marktleider – om op maat gemaakte, nauwkeurige en hoogwaardige datasets te leveren voor training en testen voor AI-projecten.
Door natuurlijke taalverwerking te combineren, kunnen we gepersonaliseerde ervaringen bieden door te helpen bij het ontwikkelen van nauwkeurige spraaktoepassingen die menselijke gesprekken effectief nabootsen. We gebruiken een hele reeks hoogwaardige technologieën om klantervaringen van hoge kwaliteit te leveren. NLP leert machines om menselijke talen te interpreteren en met mensen om te gaan.
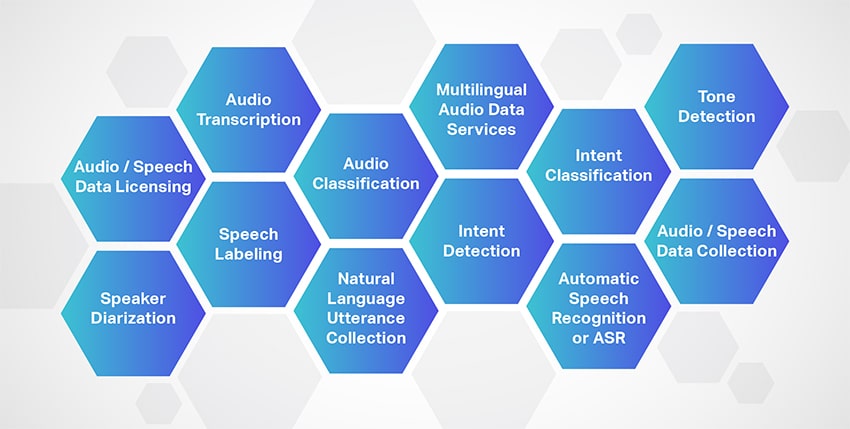
Audiotranscriptie
Shaip is een toonaangevende audiotranscriptieserviceprovider die een verscheidenheid aan spraak-/audiobestanden biedt voor alle soorten projecten. Daarnaast biedt Shaip een 100% door mensen gegenereerde transcriptieservice om audio- en videobestanden - interviews, seminars, lezingen, podcasts, enz. om te zetten in gemakkelijk leesbare tekst.
Spraaklabeling
Shaip biedt uitgebreide spraaklabelservices door de geluiden en spraak in een audiobestand vakkundig te scheiden en elk bestand te labelen. Door soortgelijke audiogeluiden nauwkeurig te scheiden en te annoteren,
Luidsprekerdiarisatie
De expertise van Sharp strekt zich uit tot het aanbieden van uitstekende oplossingen voor het diariseren van sprekers door de audio-opname te segmenteren op basis van hun bron. Bovendien worden de luidsprekergrenzen nauwkeurig geïdentificeerd en geclassificeerd, zoals luidspreker 1, luidspreker 2, muziek, achtergrondgeluid, voertuiggeluiden, stilte en meer, om het aantal luidsprekers te bepalen.
Audio Classificatie
Annotatie begint met het classificeren van audiobestanden in vooraf bepaalde categorieën. De categorieën zijn voornamelijk afhankelijk van de vereisten van het project en omvatten doorgaans de intentie van de gebruiker, taal, semantische segmentatie, achtergrondgeluid, het totale aantal sprekers en meer.
Verzameling van natuurlijke taaluitingen/ Wake-up Words
Het is moeilijk te voorspellen dat de cliënt bij het stellen van een vraag of het initiëren van een verzoek altijd soortgelijke woorden zal kiezen. Bijvoorbeeld: "Waar is het dichtstbijzijnde restaurant?" "Vind restaurants bij mij in de buurt" of "Is er een restaurant in de buurt?"
Alle drie de uitingen hebben dezelfde bedoeling, maar zijn anders geformuleerd. Door middel van permutatie en combinatie zullen de deskundige gespreks-ai-specialisten van Shaip alle mogelijke combinaties identificeren om hetzelfde verzoek te formuleren. Shaip verzamelt en annoteert uitingen en wakkere woorden, met de nadruk op semantiek, context, toon, dictie, timing, klemtoon en dialecten.
Meertalige audiogegevensservices
Meertalige audiogegevensservices zijn een ander zeer geprefereerd aanbod van Shaip, aangezien we een team van gegevensverzamelaars hebben die audiogegevens verzamelen in meer dan 150 talen en dialecten over de hele wereld.
Intentiedetectie
Menselijke interacties en communicatie zijn vaak ingewikkelder dan we ze op prijs stellen. En deze aangeboren complicatie maakt het moeilijk om een ML-model te trainen om menselijke spraak nauwkeurig te begrijpen.
Bovendien kunnen verschillende mensen uit dezelfde demografische of verschillende demografische groepen dezelfde intentie of hetzelfde sentiment anders uiten. Het spraakherkenningssysteem moet dus worden getraind om gemeenschappelijke bedoelingen te herkennen, ongeacht de demografie.
Om ervoor te zorgen dat u een eersteklas ML-model kunt trainen en ontwikkelen, bieden onze logopedisten uitgebreide en diverse datasets om het systeem te helpen de verschillende manieren te identificeren waarop mensen dezelfde intentie uitdrukken.
Intentclassificatie
Net als bij het identificeren van dezelfde intentie van verschillende mensen, moeten uw chatbots ook worden getraind om opmerkingen van klanten in verschillende categorieën te categoriseren - vooraf door u bepaald. Elke chatbot of virtuele assistent is ontworpen en ontwikkeld met een specifiek doel. Shaip kan desgewenst de intentie van de gebruiker classificeren in vooraf gedefinieerde categorieën.
Automatische spraakherkenning of ASR
Spraakherkenning” verwijst naar het omzetten van gesproken woorden in de tekst; stemherkenning en sprekeridentificatie zijn echter bedoeld om zowel gesproken inhoud als de identiteit van de spreker te identificeren. De nauwkeurigheid van ASR wordt bepaald door verschillende parameters, zoals luidsprekervolume, achtergrondgeluid, opnameapparatuur, enz.
Toon detectie
Een ander interessant facet van menselijke interactie is de toon - we herkennen intrinsiek de betekenis van woorden, afhankelijk van de toon waarop ze worden uitgesproken. Wat we zeggen is belangrijk, maar hoe we die woorden zeggen, brengen ook betekenis over.
Bijvoorbeeld een eenvoudige zin als 'Wat een vreugde!' kan een uitroep van geluk zijn en kan ook sarcastisch bedoeld zijn. Het hangt af van de toon en de spanning.
'Wat doe jij?'
'Wat doe jij?'
Beide zinnen hebben de exacte woorden, maar de nadruk op de woorden is anders, waardoor de hele betekenis van de zinnen verandert. De chatbot is getraind om geluk, sarcasme, boosheid, irritatie en meer uitingen te herkennen. Hier komt de expertise van de logopedisten en annotators van Sharp om de hoek kijken.
Licenties voor audio-/spraakgegevens
Shaip biedt ongeëvenaarde standaard kwaliteit spraakdatasets die kunnen worden aangepast aan de specifieke behoeften van uw project. De meeste van onze datasets passen in elk budget en de data is schaalbaar om aan alle toekomstige projecteisen te voldoen. We bieden 40k+ uur aan kant-en-klare spraakdatasets in meer dan 100 dialecten in meer dan 50 talen. We bieden ook een reeks audiotypes, waaronder spontane, monologen, scripts en wake-up-woorden. Bekijk de hele Gegevenscatalogus.
Audio-/spraakgegevensverzameling
Wanneer er een tekort is aan spraakdatasets van hoge kwaliteit, kan de resulterende spraakoplossing vol problemen zitten en een gebrek aan betrouwbaarheid hebben. Shaip is een van de weinige providers die meertalige audiocollecties, audiotranscriptie en annotatietools en diensten die volledig aanpasbaar zijn voor het project.
Spraakgegevens kunnen worden gezien als een spectrum, gaande van natuurlijke spraak aan de ene kant tot onnatuurlijke spraak aan de andere kant. Bij natuurlijke spraak laat u de spreker op een spontane, gemoedelijke manier praten. Aan de andere kant klinkt onnatuurlijke spraak beperkt als de spreker een script voorleest. Ten slotte worden sprekers aangezet om in het midden van het spectrum op gecontroleerde wijze woorden of zinsdelen uit te spreken.
De expertise van Sharp strekt zich uit tot het leveren van verschillende typen spraakdatasets in meer dan 150 talen

































Succesverhalen
We hebben samengewerkt met enkele van de beste bedrijven en merken en hebben hen voorzien van conversatie-AI-oplossingen van de hoogste orde.
Enkele van onze succesverhalen zijn:
- We hadden een dataset voor spraakherkenning ontwikkeld met meer dan 10,000 uur aan meertalige transcripties, gesprekken en audiobestanden om een live chatbot te trainen en te bouwen.
- We hebben een hoogwaardige dataset van duizenden gesprekken van 1000 beurten per gesprek gebouwd die worden gebruikt voor training van verzekeringschatbots.
- Ons team van meer dan 3000 taalexperts leverde meer dan 1000 uur aan audiobestanden en transcripties in 27 moedertalen voor het trainen en testen van een digitale assistent.
- Ons team van annotators en taalexperts verzamelde en leverde ook snel 20,000 en meer uren aan uitingen in meer dan 27 wereldwijde talen.
- Onze services voor automatische spraakherkenning zijn een van de meest geprefereerde in de branche. We hebben betrouwbaar gelabelde audiobestanden geleverd, waarbij specifieke aandacht is besteed aan uitspraak, toon en intentie met behulp van een breed scala aan transcripties en lexicons van verschillende sprekerssets om de betrouwbaarheid van ASR-modellen te verbeteren.
Onze succesverhalen komen voort uit de toewijding van ons team om onze klanten altijd de beste services te bieden met behulp van de nieuwste technologieën. Wat ons anders maakt, is dat ons werk wordt ondersteund door deskundige annotators die onbevooroordeelde en nauwkeurige datasets van gouden standaardannotaties leveren.
Ons team voor gegevensverzameling van meer dan 30,000 bijdragers kan hoogwaardige datasets zoeken, schalen en leveren die helpen bij de snelle implementatie van ML-modellen. Bovendien werken we op het nieuwste op AI gebaseerde platform en hebben we de mogelijkheid om sneller dan onze naaste concurrenten versnelde oplossingen voor spraakgegevens aan te bieden aan bedrijven.
