
Kunstmatige intelligentie zorgt voor een revolutie in de muziekindustrie en biedt geautomatiseerde compositie-, mastering- en uitvoeringstools. AI-algoritmen genereren nieuwe composities, voorspellen hits en personaliseren de luisterervaring, waardoor muziekproductie, -distributie en -consumptie worden getransformeerd. Deze opkomende technologie biedt zowel opwindende kansen als uitdagende ethische dilemma's.
Machine learning (ML)-modellen hebben trainingsgegevens nodig om effectief te kunnen functioneren, zoals een componist muzieknoten nodig heeft om een symfonie te schrijven. In de muziekwereld, waar melodie, ritme en emotie met elkaar verweven zijn, kan het belang van kwaliteitsvolle trainingsgegevens niet genoeg worden benadrukt. Het vormt de ruggengraat van het ontwikkelen van robuuste en nauwkeurige ML-modellen voor muziek voor voorspellende analyse, genreclassificatie of automatische transcriptie.
Gegevens, de levensader van ML-modellen
Machine learning is inherent datagestuurd. Deze rekenmodellen leren patronen uit de gegevens, waardoor ze voorspellingen of beslissingen kunnen doen. Voor muziek-ML-modellen komen trainingsgegevens vaak in gedigitaliseerde muziektracks, songteksten, metadata of een combinatie van deze elementen. De kwaliteit, kwantiteit en diversiteit van deze gegevens hebben een aanzienlijke invloed op de effectiviteit van het model.

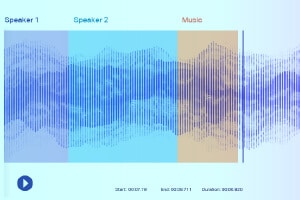
Geluidsetikettering
Met geluidslabeling krijgen de data-annotators een opname en moeten ze alle benodigde geluiden scheiden en labelen. Dit kunnen bijvoorbeeld bepaalde trefwoorden zijn of het geluid van een specifiek muziekinstrument.

Muziekclassificatie
Data-annotators kunnen genres of instrumenten markeren in dit soort audio-annotatie. Muziekclassificatie is erg handig voor het organiseren van muziekbibliotheken en het verbeteren van gebruikersaanbevelingen.

Segmentatie op fonetisch niveau
Label en classificatie van fonetische segmenten op de golfvormen en spectrogrammen van opnames van individuen die acapella zingen.
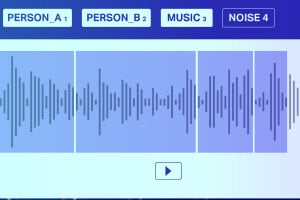
Geluidsclassificatie
Afgezien van stilte/witte ruis, bestaat een audiobestand doorgaans uit de volgende geluidstypen Spraak, Babble, Muziek en Ruis. Annoteer muzieknoten nauwkeurig voor een grotere nauwkeurigheid.
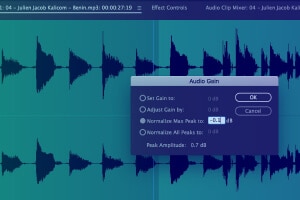
Metadata-informatie vastleggen
Leg belangrijke informatie vast, zoals starttijd, eindtijd, segment-ID, luidheidsniveau, primair geluidstype, taalcode, luidspreker-ID en andere transcriptieconventies, enz.


