



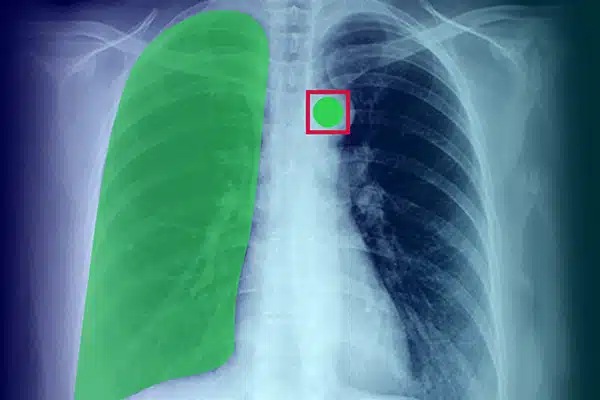
Annotatie afbeelding
Verbeter medische AI door visuele gegevens van röntgenfoto's, CT-scans en MRI's te annoteren. Zorg ervoor dat AI-modellen uitstekend presteren bij diagnostiek en behandeling, op basis van deskundige datalabeling. Behaal betere patiëntresultaten met superieure beeldvormingsinzichten.
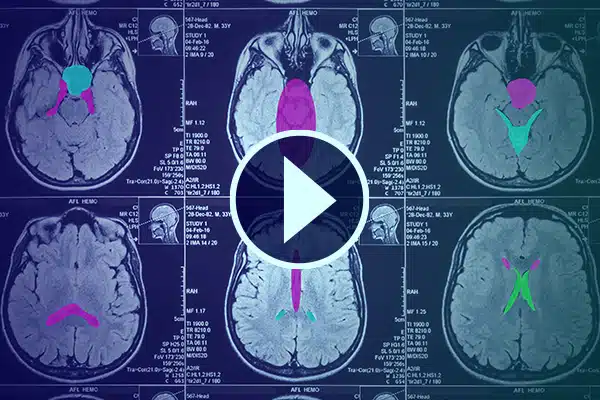
Videoannotatie
Verbeter AI in de gezondheidszorg met gedetailleerde videoannotatie. Verscherp het AI-leren met classificaties en segmentaties in medische beelden. Verbeter uw chirurgische AI en patiëntmonitoring voor verbeterde gezondheidszorgverlening en diagnostiek.
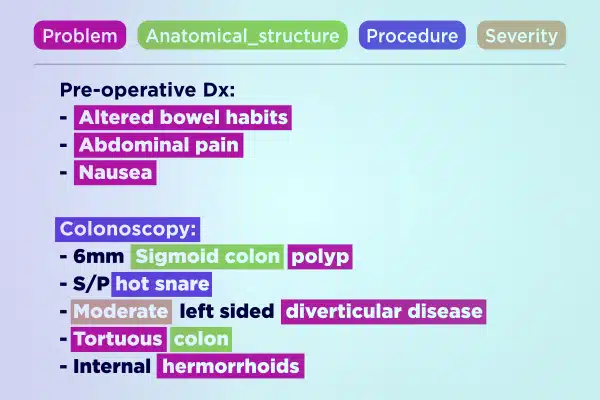
Tekstannotatie
Stroomlijn de medische AI-ontwikkeling met vakkundig geannoteerde tekstgegevens. Ontleed en verrijk snel grote tekstvolumes, van handgeschreven notities tot verzekeringsrapporten. Zorg voor nauwkeurige en bruikbare inzichten voor vooruitgang in de gezondheidszorg.

Audio-annotatie
Maak gebruik van NLP-expertise om medische audiogegevens nauwkeurig te annoteren en te labelen. Creëer stemgestuurde systemen voor naadloze klinische operaties en integreer AI in verschillende stemgestuurde gezondheidszorgproducten. Verbeter de diagnostische precisie met deskundige beheer van audiogegevens.

Medische codering
Stroomlijn medische documentatie door deze om te zetten in universele codes met medische AI-codering. Zorg voor nauwkeurigheid, verbeter de factureringsefficiëntie en ondersteun een naadloze levering van gezondheidszorgdiensten met geavanceerde AI-ondersteuning bij het coderen van medische dossiers.

Fase 1: Expertise in het technische domein (inzicht in richtlijnen voor bereik en annotaties)

Fase 2: Training van geschikte middelen voor het project

Fase 3: Feedbackcyclus en QA van de geannoteerde documenten
Radiologie
Onze radiologische beeldannotatieservice verscherpt de AI-diagnostiek en omvat een extra laag expertise. Elke röntgenfoto, MRI- en CT-scan wordt zorgvuldig geëtiketteerd en beoordeeld door een materiedeskundige. Deze extra stap in training en review vergroot het vermogen van de AI om afwijkingen en ziekten op te sporen. Het verbetert de nauwkeurigheid vóór levering aan onze klanten.

Cardiologie
Onze op cardiologie gerichte beeldannotatie verscherpt de AI-diagnostiek. We schakelen cardiologie-experts in die complexe hartgerelateerde beelden labelen en onze AI-modellen trainen. Voordat we gegevens naar klanten sturen, beoordelen deze specialisten elke afbeelding om de hoogste nauwkeurigheid te garanderen. Dit proces stelt AI in staat hartaandoeningen nauwkeuriger te detecteren.
Tandheelkunde
Onze beeldannotatieservice in de tandheelkunde labelt tandheelkundige beelden om de AI-diagnostische hulpmiddelen te verbeteren. Door tandbederf, uitlijningsproblemen en andere tandheelkundige aandoeningen nauwkeurig te identificeren, stellen onze MKB-bedrijven AI in staat om de patiëntresultaten te verbeteren en tandartsen te ondersteunen bij nauwkeurige behandelplanning en vroege detectie.


















Mensen
Toegewijde en getrainde teams:
- 30,000+ medewerkers voor gegevenscreatie, labeling en QA
- Gecertificeerd projectmanagementteam
- Ervaren productontwikkelingsteam
- Talentpool Sourcing & Onboarding-team

Proces
De hoogste procesefficiëntie wordt gegarandeerd met:
- Robuust 6 Sigma Stage-Gate-proces
- Een toegewijd team van 6 Sigma black belts – Key process owners & Quality compliance
- Continue verbetering en feedbacklus

Platform
Het gepatenteerde platform biedt voordelen:
- Webgebaseerd end-to-end platform
- Onberispelijke kwaliteit
- Snellere TAT
- Naadloze levering



