Wat is NLP?
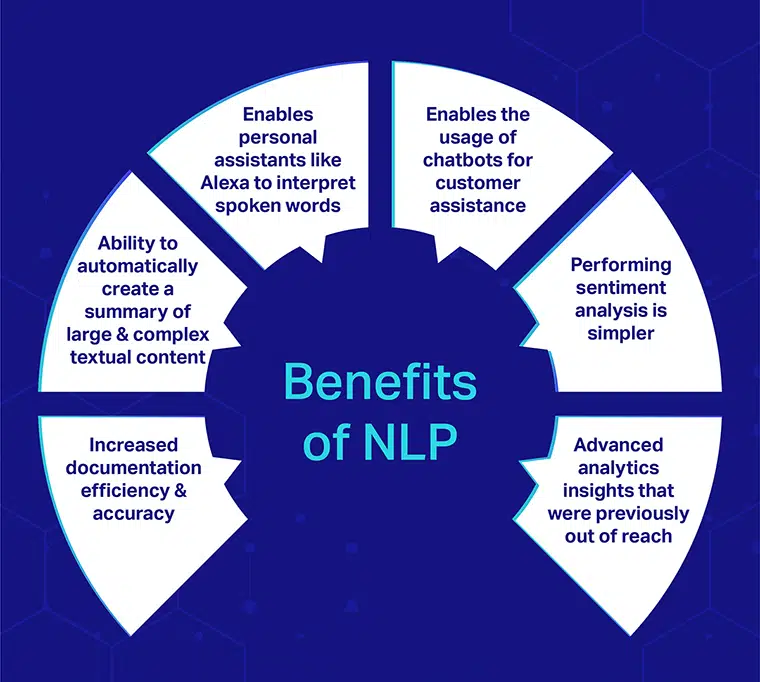
Natural Language Processing (NLP) is een onderdeel van kunstmatige intelligentie (AI). Het stelt robots in staat om menselijke taal te analyseren en te begrijpen, waardoor ze repetitieve activiteiten kunnen uitvoeren zonder menselijke tussenkomst. Voorbeelden hiervan zijn machinevertaling, samenvatting, ticketclassificatie en spellingcontrole.
Natural Language Processing (NLP) is het vermogen van een computer om menselijke taal te analyseren en te begrijpen. NLP is een subset van kunstmatige intelligentie gericht op menselijke taal en is nauw verwant aan computationele taalkunde, die zich meer richt op statistische en formele benaderingen voor het begrijpen van taal.
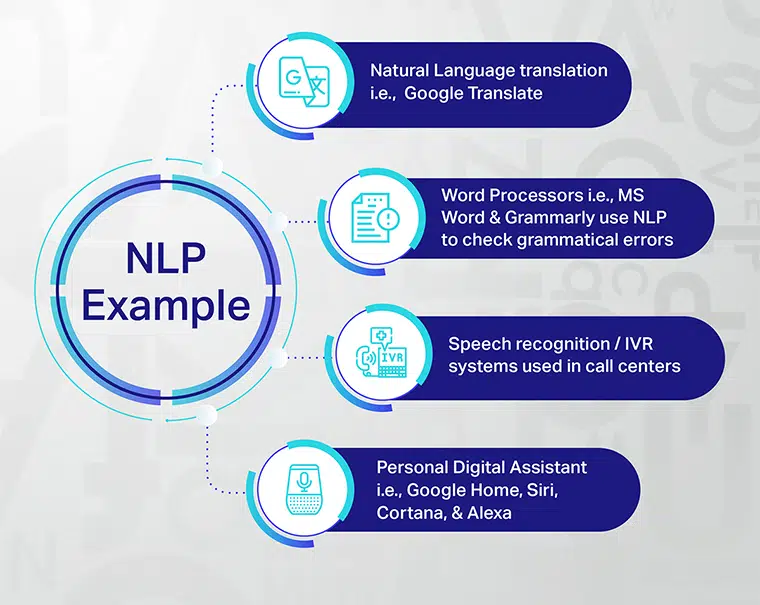
NLP wordt meestal gebruikt voor documentsamenvatting, tekstclassificatie, onderwerpdetectie en -tracking, machinevertaling, spraakherkenning en nog veel meer.
Hoe werkt NLP?
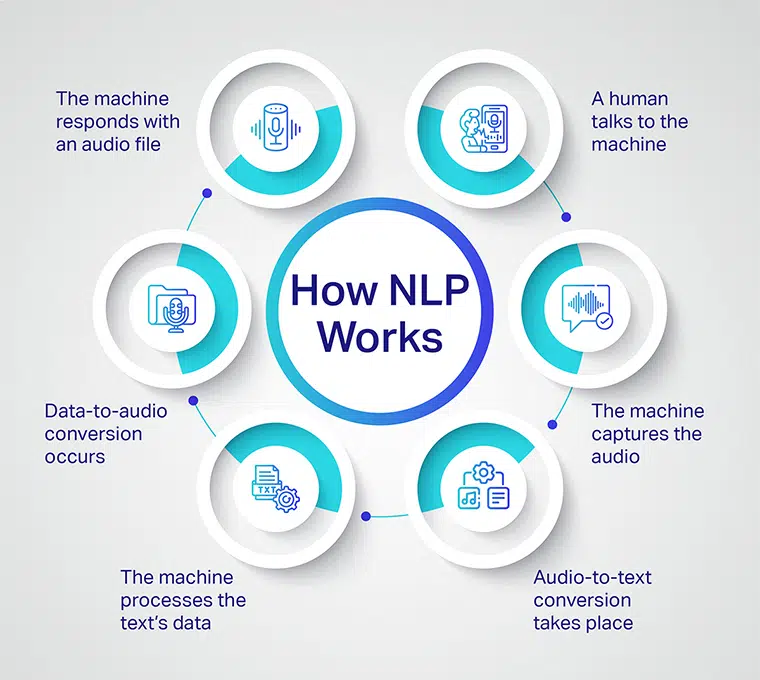
NLP-systemen gebruiken machine learning-algoritmen om grote hoeveelheden ongestructureerde gegevens te analyseren en relevante informatie te extraheren. De algoritmen zijn getraind om patronen te herkennen en conclusies te trekken op basis van die patronen. Dit is hoe het werkt:
- De gebruiker moet een zin invoeren in het Natural Language Processing (NLP)-systeem.
- Het NLP-systeem splitst de zin vervolgens op in kleinere delen van woorden, tokens genaamd, en converteert audio naar tekst.
- Vervolgens verwerkt de machine de tekstgegevens en maakt een audiobestand op basis van de verwerkte gegevens.
- De machine reageert met een audiobestand op basis van verwerkte tekstgegevens.

NLP-marktomvang en -groei
Kunstmatige intelligentie wordt het volgende grote ding in de technische wereld. Met zijn vermogen om menselijk gedrag te begrijpen en dienovereenkomstig te handelen, is AI al een integraal onderdeel van ons dagelijks leven geworden. Het gebruik van AI is geëvolueerd, met als nieuwste golf natuurlijke taalverwerking (NLP).
De wereldwijde NLP-marktomvang wordt geschat op USD 15.7 miljard in 2022 en zal naar verwachting groeien met een CAGR van meer dan 25% in de prognoseperiode 2022-2027. De markt zal naar verwachting in 49.4 2027 miljard USD bereiken bij een CAGR van 25.7%.