
AI, Big Data en Machine Learning blijven beleidsmakers, bedrijven, wetenschap, mediahuizen en een verscheidenheid aan industrieën over de hele wereld beïnvloeden. Rapporten suggereren dat de wereldwijde acceptatiegraad van AI momenteel is 35% in 2022 – maar liefst 4% stijging vanaf 2021. Nog eens 42% van de bedrijven onderzoekt naar verluidt de vele voordelen van AI voor hun bedrijf.
Aansturen van de vele AI-initiatieven en Machine leren oplossingen zijn gegevens. AI kan maar zo goed zijn als de gegevens die het algoritme voeden. Gegevens van lage kwaliteit kunnen leiden tot resultaten van lage kwaliteit en onnauwkeurige voorspellingen.
Hoewel er veel aandacht is besteed aan de ontwikkeling van ML- en AI-oplossingen, ontbreekt het besef van wat kwalificeert als een kwaliteitsdataset. In dit artikel navigeren we door de tijdlijn van hoogwaardige AI-trainingsgegevens en de toekomst van AI identificeren door inzicht te krijgen in gegevensverzameling en training.
Definitie van AI-trainingsgegevens
Bij het bouwen van een ML-oplossing zijn de kwantiteit en de kwaliteit van de trainingsdataset van belang. Het ML-systeem vereist niet alleen grote hoeveelheden dynamische, onbevooroordeelde en waardevolle trainingsgegevens, maar het heeft er ook veel van nodig.
Maar wat zijn AI-trainingsgegevens?
AI-trainingsgegevens zijn een verzameling gelabelde gegevens die worden gebruikt om het ML-algoritme te trainen om nauwkeurige voorspellingen te doen. Het ML-systeem probeert patronen te herkennen en te identificeren, relaties tussen parameters te begrijpen, noodzakelijke beslissingen te nemen en te evalueren op basis van de trainingsgegevens.
Neem bijvoorbeeld de zelfrijdende auto's. De trainingsgegevensset voor een zelfrijdend ML-model moet gelabelde afbeeldingen en video's van auto's, voetgangers, straatnaamborden en andere voertuigen bevatten.
Kortom, om de kwaliteit van het ML-algoritme te verbeteren, hebt u grote hoeveelheden goed gestructureerde, geannoteerde en gelabelde trainingsgegevens nodig.
Het belang van kwaliteitsvolle trainingsgegevens en de evolutie ervan
Hoogwaardige trainingsgegevens zijn de belangrijkste input bij de ontwikkeling van AI- en ML-apps. Gegevens worden verzameld uit verschillende bronnen en gepresenteerd in een ongeorganiseerde vorm die niet geschikt is voor machine learning-doeleinden. Hoogwaardige trainingsgegevens - gelabeld, geannoteerd en getagd - zijn altijd in een georganiseerd formaat - ideaal voor ML-training.
Hoogwaardige trainingsgegevens maken het voor het ML-systeem gemakkelijker om objecten te herkennen en ze te classificeren op basis van vooraf bepaalde kenmerken. De dataset kan slechte modeluitkomsten opleveren als de classificatie niet nauwkeurig is.
De vroege dagen van AI-trainingsgegevens
Ondanks dat AI de huidige zaken- en onderzoekswereld domineert, domineerden de vroege dagen vóór ML Artificial Intelligence was heel anders.
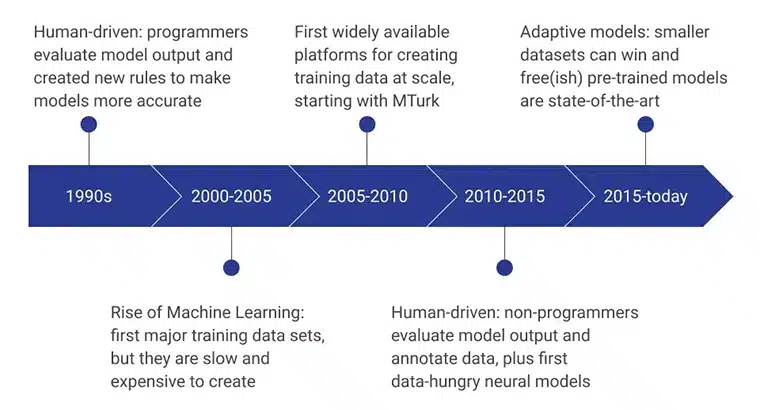
De beginfasen van AI-trainingsgegevens werden aangestuurd door menselijke programmeurs die de modeloutput evalueerden door consequent nieuwe regels te bedenken die het model efficiënter maakten. In de periode 2000 - 2005 werd de eerste grote dataset gemaakt, en het was een extreem langzaam, afhankelijk van hulpbronnen en duur proces. Het leidde tot de ontwikkeling van trainingsdatasets op grote schaal, en Amazon's MTurk speelde een belangrijke rol bij het veranderen van de perceptie van mensen ten aanzien van gegevensverzameling. Tegelijkertijd namen ook menselijke labels en annotaties een hoge vlucht.
De volgende jaren waren gericht op niet-programmeurs die de datamodellen creëerden en evalueerden. Momenteel ligt de focus op vooraf getrainde modellen die zijn ontwikkeld met behulp van geavanceerde methoden voor het verzamelen van trainingsgegevens.
Kwantiteit boven kwaliteit
Bij het beoordelen van de integriteit van AI-trainingsdatasets vroeger, concentreerden datawetenschappers zich op Hoeveelheid AI-trainingsgegevens boven kwaliteit.
Er was bijvoorbeeld een algemene misvatting dat grote databases nauwkeurige resultaten opleveren. De enorme hoeveelheid gegevens werd beschouwd als een goede indicator van de waarde van gegevens. Kwantiteit is slechts een van de belangrijkste factoren die de waarde van de dataset bepalen – de rol van datakwaliteit werd erkend.
Het besef dat data kwaliteit afhankelijk van de volledigheid van de gegevens, nam de betrouwbaarheid, validiteit, beschikbaarheid en tijdigheid toe. Het belangrijkste was dat de geschiktheid van de gegevens voor het project de kwaliteit van de verzamelde gegevens bepaalde.
Beperkingen van vroege AI-systemen vanwege slechte trainingsgegevens
Slechte trainingsgegevens, in combinatie met het ontbreken van geavanceerde computersystemen, waren een van de redenen voor verschillende onvervulde beloften van vroege AI-systemen.
Vanwege het gebrek aan hoogwaardige trainingsgegevens konden ML-oplossingen visuele patronen niet nauwkeurig identificeren, waardoor de ontwikkeling van neuraal onderzoek werd vertraagd. Hoewel veel onderzoekers de belofte van gesproken taalherkenning onderkenden, kon onderzoek naar of ontwikkeling van hulpmiddelen voor spraakherkenning niet tot wasdom komen dankzij het gebrek aan spraakdatasets. Een ander groot obstakel bij het ontwikkelen van geavanceerde AI-tools was het gebrek aan reken- en opslagmogelijkheden van de computers.
De verschuiving naar hoogwaardige trainingsgegevens
Er was een duidelijke verschuiving in het besef dat de kwaliteit van de dataset ertoe doet. Om ervoor te zorgen dat het ML-systeem menselijke intelligentie en besluitvormingsmogelijkheden nauwkeurig nabootst, moet het gedijen op grote hoeveelheden trainingsgegevens van hoge kwaliteit.
Beschouw uw ML-gegevens als een enquête: hoe groter de gegevens monster grootte, hoe beter de voorspelling. Als de voorbeeldgegevens niet alle variabelen bevatten, herkent het mogelijk geen patronen of leidt het tot onnauwkeurige conclusies.
Vooruitgang in AI-technologie en de behoefte aan betere trainingsgegevens
 Door de vooruitgang in AI-technologie neemt de behoefte aan hoogwaardige trainingsgegevens toe.
Door de vooruitgang in AI-technologie neemt de behoefte aan hoogwaardige trainingsgegevens toe.Het inzicht dat betere trainingsgegevens de kans op betrouwbare ML-modellen vergroten, leidde tot betere methoden voor het verzamelen, annoteren en labelen van gegevens. De kwaliteit en relevantie van de gegevens hadden een directe invloed op de kwaliteit van het AI-model.
 Door de vooruitgang in AI-technologie neemt de behoefte aan hoogwaardige trainingsgegevens toe.
Door de vooruitgang in AI-technologie neemt de behoefte aan hoogwaardige trainingsgegevens toe.Meer focus op datakwaliteit en nauwkeurigheid
Om ervoor te zorgen dat het ML-model nauwkeurige resultaten gaat opleveren, wordt het gevoed met kwaliteitsdatasets die iteratieve stappen voor gegevensverfijning doorlopen.
Een mens kan bijvoorbeeld een specifiek hondenras binnen een paar dagen nadat hij kennis heeft gemaakt met het ras herkennen - door middel van foto's, video's of persoonlijk. Mensen putten uit hun ervaring en gerelateerde informatie om deze kennis te onthouden en op te halen wanneer dat nodig is. Toch werkt het niet zo gemakkelijk voor een Machine. De machine moet worden gevoed met duidelijk geannoteerde en gelabelde afbeeldingen – honderden of duizenden – van dat specifieke ras en andere rassen om de verbinding te kunnen maken.
Een AI-model voorspelt de uitkomst door de getrainde informatie te correleren met de informatie die in de training wordt gepresenteerd echte wereld. Het algoritme wordt onbruikbaar als de trainingsgegevens geen relevante informatie bevatten.
Belang van diverse en representatieve opleidingsgegevens
Meer gegevensdiversiteit vergroot ook de competentie, vermindert vooringenomenheid en bevordert een eerlijke weergave van alle scenario's. Als het AI-model wordt getraind met behulp van een homogene dataset, kunt u er zeker van zijn dat de nieuwe applicatie alleen voor een specifiek doel werkt en een specifieke populatie bedient.Een dataset kan gericht zijn op een bepaalde populatie, ras, geslacht, keuze en intellectuele meningen, wat kan leiden tot een onnauwkeurig model.
Het is belangrijk om ervoor te zorgen dat het hele proces voor het verzamelen van gegevens, inclusief het selecteren van de onderwerppool, curatie, annotatie en labeling, voldoende divers, evenwichtig en representatief is voor de populatie.
 Meer gegevensdiversiteit vergroot ook de competentie, vermindert vooringenomenheid en bevordert een eerlijke weergave van alle scenario's. Als het AI-model wordt getraind met behulp van een homogene dataset, kunt u er zeker van zijn dat de nieuwe applicatie alleen voor een specifiek doel werkt en een specifieke populatie bedient.
Meer gegevensdiversiteit vergroot ook de competentie, vermindert vooringenomenheid en bevordert een eerlijke weergave van alle scenario's. Als het AI-model wordt getraind met behulp van een homogene dataset, kunt u er zeker van zijn dat de nieuwe applicatie alleen voor een specifiek doel werkt en een specifieke populatie bedient.De toekomst van AI-trainingsgegevens
Het toekomstige succes van AI-modellen hangt af van de kwaliteit en kwantiteit van trainingsgegevens die worden gebruikt om de ML-algoritmen te trainen. Het is van cruciaal belang om te erkennen dat deze relatie tussen datakwaliteit en -kwantiteit taakspecifiek is en geen definitief antwoord heeft.
Uiteindelijk wordt de adequaatheid van een trainingsgegevensset bepaald door het vermogen om betrouwbaar goed te presteren voor het doel waarvoor het is gebouwd.
Vooruitgang in gegevensverzameling en annotatietechnieken
Aangezien ML gevoelig is voor de ingevoerde gegevens, is het essentieel om het beleid voor gegevensverzameling en annotatie te stroomlijnen. Fouten bij het verzamelen van gegevens, curatie, verkeerde voorstelling van zaken, onvolledige metingen, onnauwkeurige inhoud, gegevensduplicatie en foutieve metingen dragen bij aan onvoldoende gegevenskwaliteit.
Geautomatiseerde gegevensverzameling door middel van datamining, webschrapen en gegevensextractie maakt de weg vrij voor snellere gegevensgeneratie. Bovendien fungeren voorverpakte datasets als een quick-fix techniek voor het verzamelen van gegevens.
Crowdsourcing is een andere baanbrekende methode voor het verzamelen van gegevens. Hoewel de waarheidsgetrouwheid van de gegevens niet kan worden gegarandeerd, is het een uitstekend hulpmiddel om het publieke imago te verzamelen. Eindelijk gespecialiseerd het verzamelen van gegevens experts leveren ook gegevens die voor specifieke doeleinden zijn verzameld.
Meer nadruk op ethische overwegingen in trainingsgegevens
Met de snelle vooruitgang in AI zijn er verschillende ethische kwesties naar voren gekomen, vooral bij het verzamelen van trainingsgegevens. Enkele ethische overwegingen bij het verzamelen van trainingsgegevens zijn onder meer geïnformeerde toestemming, transparantie, vooringenomenheid en gegevensprivacy.Aangezien gegevens nu alles omvatten, van gezichtsopnamen, vingerafdrukken, stemopnamen en andere kritieke biometrische gegevens, wordt het van cruciaal belang om ervoor te zorgen dat de wettelijke en ethische praktijken worden nageleefd om dure rechtszaken en reputatieschade te voorkomen.
Het potentieel voor nog betere kwaliteit en diverse trainingsgegevens in de toekomst
Er is een enorm potentieel voor hoogwaardige en diverse trainingsgegevens in de toekomst. Dankzij het besef van datakwaliteit en de beschikbaarheid van dataproviders die inspelen op de kwaliteitseisen van AI-oplossingen.
Huidige gegevensleveranciers zijn bedreven in het gebruik van baanbrekende technologieën om op ethische en legale wijze enorme hoeveelheden uiteenlopende gegevenssets te verkrijgen. Ze hebben ook interne teams om de gegevens op maat voor verschillende ML-projecten te labelen, te annoteren en te presenteren.
 Met de snelle vooruitgang in AI zijn er verschillende ethische kwesties naar voren gekomen, vooral bij het verzamelen van trainingsgegevens. Enkele ethische overwegingen bij het verzamelen van trainingsgegevens zijn onder meer geïnformeerde toestemming, transparantie, vooringenomenheid en gegevensprivacy.
Met de snelle vooruitgang in AI zijn er verschillende ethische kwesties naar voren gekomen, vooral bij het verzamelen van trainingsgegevens. Enkele ethische overwegingen bij het verzamelen van trainingsgegevens zijn onder meer geïnformeerde toestemming, transparantie, vooringenomenheid en gegevensprivacy.Conclusie
Het is belangrijk om samen te werken met betrouwbare leveranciers met een scherp begrip van gegevens en kwaliteit high-end AI-modellen ontwikkelen. Shaip is het belangrijkste annotatiebedrijf dat bedreven is in het leveren van op maat gemaakte gegevensoplossingen die voldoen aan de behoeften en doelen van uw AI-project. Werk met ons samen en ontdek de competenties, toewijding en samenwerking die we ter tafel brengen.


