
Wat is tekstannotatie in machine learning?
Tekstannotatie in machine learning verwijst naar het toevoegen van metadata of labels aan onbewerkte tekstuele gegevens om gestructureerde datasets te creëren voor het trainen, evalueren en verbeteren van machine learning-modellen. Het is een cruciale stap in natuurlijke taalverwerkingstaken (NLP), omdat het algoritmen helpt bij het begrijpen, interpreteren en voorspellen van tekst op basis van tekstinvoer.
Tekstannotatie is belangrijk omdat het de kloof helpt overbruggen tussen ongestructureerde tekstuele gegevens en gestructureerde, machineleesbare gegevens. Hierdoor kunnen machine learning-modellen patronen uit de geannoteerde voorbeelden leren en generaliseren.
Annotaties van hoge kwaliteit zijn essentieel voor het bouwen van nauwkeurige en robuuste modellen. Daarom is zorgvuldige aandacht voor detail, consistentie en domeinexpertise essentieel bij tekstannotatie.
Soorten tekstannotaties

Bij het trainen van NLP-algoritmen is het essentieel om grote geannoteerde tekstdatasets te hebben die zijn afgestemd op de unieke behoeften van elk project. Voor ontwikkelaars die dergelijke datasets willen maken, volgt hier een eenvoudig overzicht van vijf populaire typen tekstannotaties.

Sentimentannotatie
Sentimentannotatie identificeert de onderliggende emoties, meningen of attitudes van een tekst. Annotators labelen tekstsegmenten met positieve, negatieve of neutrale sentiment-tags. Sentimentanalyse, een belangrijke toepassing van dit annotatietype, wordt veel gebruikt bij het monitoren van sociale media, analyse van klantfeedback en marktonderzoek.
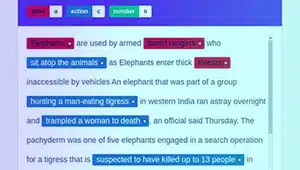
Intentie annotatie
Intent-annotatie is bedoeld om het doel of doel achter een bepaalde tekst vast te leggen. Bij dit type annotatie wijzen annotators labels toe aan tekstsegmenten die specifieke gebruikersintenties vertegenwoordigen, zoals het vragen om informatie, het vragen om iets of het uiten van een voorkeur.
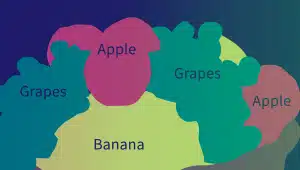
Semantische annotatie
Semantische annotatie identificeert de betekenis en relaties tussen woorden, woordgroepen en zinnen. Annotators gebruiken verschillende technieken, zoals tekstsegmentatie, documentanalyse en tekstextractie, om de semantische eigenschappen van tekstelementen te labelen en te classificeren.

Entiteit annotatie
Annotatie van entiteiten is cruciaal bij het maken van datasets voor chatbottraining en andere NLP-gegevens. Het gaat om het vinden en labelen van entiteiten in tekst. Soorten entiteitannotaties zijn onder meer:

Taalkundige annotatie
Taalkundige annotatie behandelt de structurele en grammaticale aspecten van taal. Het omvat verschillende subtaken, zoals part-of-speech tagging, syntactische parsing en morfologische analyse.

Verzekering
Tekstaantekeningen helpen verzekeringsmaatschappijen bij het analyseren van klantfeedback, het verwerken van claims en het opsporen van fraude. Door AI-modellen te gebruiken die zijn getraind op geannoteerde datasets, kunnen verzekeraars:

Bankieren
Tekstaantekeningen maken verbeterde klantenservice, fraudedetectie en documentanalyse in het bankwezen mogelijk. AI-systemen die zijn getraind op geannoteerde gegevens kunnen:

Telecom
Met tekstannotatie kunnen telecombedrijven de klantenondersteuning verbeteren, sociale media monitoren en netwerkproblemen beheren. Machine learning-modellen die zijn getraind op geannoteerde datasets kunnen:
Hoe tekstgegevens annoteren?
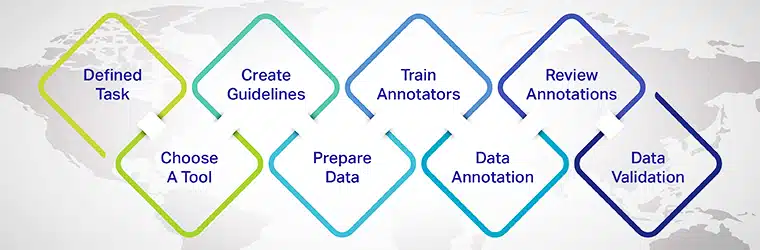
- Definieer de annotatietaak: Bepaal de specifieke NLP-taak die u wilt aanpakken, zoals sentimentanalyse, herkenning van benoemde entiteiten of tekstclassificatie.
- Kies een geschikte annotatietool: Selecteer een tool of platform voor tekstannotatie dat voldoet aan uw projectvereisten en de gewenste annotatietypen ondersteunt.
- Annotatierichtlijnen maken: Ontwikkel duidelijke en consistente richtlijnen voor annotators om te volgen, waardoor hoogwaardige en nauwkeurige annotaties worden gegarandeerd.
- Selecteer en bereid de gegevens voor: Verzamel een diverse en representatieve steekproef van onbewerkte tekstgegevens voor de annotators om aan te werken.
- Train en evalueer annotators: Bied training en continue feedback aan annotators, en zorg voor consistentie en kwaliteit in het annotatieproces.
- Annoteer de gegevens: Annotators labelen de tekst volgens de gedefinieerde richtlijnen en annotatietypes.
- Beoordeel en verfijn annotaties: Controleer en verfijn regelmatig de annotaties, pak eventuele inconsistenties of fouten aan en verbeter iteratief de dataset.
- Splits de dataset: Verdeel de geannoteerde gegevens in trainings-, validatie- en testsets om het machine learning-model te trainen en te evalueren.
Wat kan Sheip voor u doen?
Shaip biedt maatwerk oplossingen voor tekstannotatie om uw AI- en machine learning-toepassingen in verschillende industrieën van stroom te voorzien. Met een sterke focus op hoogwaardige en nauwkeurige annotaties, kan het ervaren team en het geavanceerde annotatieplatform van Shaip uiteenlopende tekstgegevens verwerken.
Of het nu gaat om sentimentanalyse, herkenning van benoemde entiteiten of tekstclassificatie, Shaip levert aangepaste datasets om het taalbegrip en de prestaties van uw AI-modellen te helpen verbeteren.
Vertrouw op Shaip om uw tekstannotatieproces te stroomlijnen en ervoor te zorgen dat uw AI-systemen hun volledige potentieel bereiken.

